

Script and deploy the data for database from SSDT project
This post is a part of the series about SSDT and database project leveraging Visual Studio.
We already know that SSDT can cover all objects but only on a database level, such as:
- tables,
- view,
- stored procedures,
- functions,
- user types,
- assemblies,
- etc.
We can not manage out of the box with SSDT is everything behind the scope, e.g.:
- SQL Logins,
- SQL Jobs,
- Extended Events.
There is another category of thing, which exist on a database level, but can’t be managed by SSDT natively.
Namely: The DATA.
It’s a very common scenario when we have a database (project) and require some data in selected tables even in the freshly deployed, empty database.
Nomenclature for these data/tables that you can meet are:
– reference data
– master data
– dictionary
Which term have you heard and is closest to you?
By default, SSDT does not support scripting or deploying the data.
Hence: the question is: how we can cope with that?
The answer is the Post-Deployment script.
Having said that – you already might know than the game is just beginning…
Post Deployment
There are several ways how to approach this problem.
I will show you some solutions I have used for projects I’ve worked for to date.
I would divide the problem into two things:
1) How to script the existing data
2) How to build a deployment of the reference data, considering the following aspects:
a) Inserting new rows
b) Update existing data (in target table)
c) Should I delete rows that don’t exist in the source?
Let’s take a look (agenda):
Type of reference data
Scenario #1 (insert new rows only)
This is probably the most common way to generate reference data.
It is not fast, but it can work for small tables. Also, any developer can write it, not just database developers.
Target is not empty, but new rows can come from the code and need to be added.
IF NOT EXISTS (SELECT 1 FROM [Person].[PhoneNumberType] WHERE [PhoneNumberTypeID] = 1) BEGIN INSERT INTO [Person].[PhoneNumberType] ([PhoneNumberTypeID], [Name], [ModifiedDate]) VALUES (1, 'Cell', '20171213 13:19:22.273') END --Repeat above block for every row in a table.
Scenario #2 (insert only) – initial load data
In this scenario, we expect to insert reference data rows only once – for the first time after the creation of a database and table. The table is empty, so that indicates whether inserting the data or not. Once done – we don’t have to touch the data as we know that the data is static in there and no one gonna changes it.
IF NOT EXISTS (SELECT TOP (1) * FROM [Person].[PhoneNumberType]) BEGIN ;WITH cte_data as (SELECT [PhoneNumberTypeID], [Name], [ModifiedDate] FROM (VALUES (1, 'Cell', '20171213 13:19:22.273') , (2, 'Home', '20171213 13:19:22.273') , (3, 'Work', '20171213 13:19:22.273') ) as v ([PhoneNumberTypeID], [Name], [ModifiedDate]) ) INSERT INTO [Person].[PhoneNumberType] ([PhoneNumberTypeID], [Name], [ModifiedDate]) SELECT [PhoneNumberTypeID], [Name], [ModifiedDate] FROM cte_data; END
A drawback of this approach: data could change accidentally by developers, external system (when should not) or undiscovered process. That’s why is better to protect these data and redeploy and overwrite all rows over and over again.
MERGE all things
What if you must “simply” reflect all you have in the source (code repository), updating whatever exists or not in the target database tables?
The things are getting complicated, right?
A MERGE statement can come with help then.
Have a look at these 2 scenarios:
Scenario #3 (Full update, including Delete)
By creating a MERGE statement we do ensure that the data is the same as in repo. Not only the new rows but also all unexpected rows which must be deleted, or changes made for existing rows which must be updated and return to the desired state. The script should do all actions at once:
- INSERT – for these rows which are in the source but not in the target yet
- UPDATE – for all existing rows
- DELETE – for all rows which present in the target but not in the source
Let’s create a code – MERGE statement for the table. Now, you will see the code created by one tool that I introduce later:
CREATE PROCEDURE [data].[Populate_Person_PhoneNumberType]
AS
BEGIN
/*
Table's data: [Person].[PhoneNumberType]
Data Source: [DEV19].[AdventureWorks2014]
Created on: 18/10/2019 15:06:49
Scripted by: DEV19\Administrator
Generated by Data Script Writer - ver. 2.0.0.0
*/
PRINT 'Populating data into [Person].[PhoneNumberType]';
IF OBJECT_ID('tempdb.dbo.#Person_PhoneNumberType') IS NOT NULL DROP TABLE #Person_PhoneNumberType;
SELECT * INTO #Person_PhoneNumberType FROM [Person].[PhoneNumberType] WHERE 0=1;
SET IDENTITY_INSERT #Person_PhoneNumberType ON;
INSERT INTO #Person_PhoneNumberType
([PhoneNumberTypeID], [Name], [ModifiedDate])
SELECT CAST([PhoneNumberTypeID] AS int) AS [PhoneNumberTypeID], [Name], [ModifiedDate] FROM
(VALUES
(1, 'Cell', '20171213 13:19:22.273')
, (2, 'Home', '20171213 13:19:22.273')
, (3, 'Work', '20171213 13:19:22.273')
) as v ([PhoneNumberTypeID], [Name], [ModifiedDate]);
SET IDENTITY_INSERT #Person_PhoneNumberType OFF;
SET IDENTITY_INSERT [Person].[PhoneNumberType] ON;
WITH cte_data as (SELECT CAST([PhoneNumberTypeID] AS int) AS [PhoneNumberTypeID], [Name], [ModifiedDate] FROM [#Person_PhoneNumberType])
MERGE [Person].[PhoneNumberType] as t
USING cte_data as s
ON t.[PhoneNumberTypeID] = s.[PhoneNumberTypeID]
WHEN NOT MATCHED BY target THEN
INSERT ([PhoneNumberTypeID], [Name], [ModifiedDate])
VALUES (s.[PhoneNumberTypeID], s.[Name], s.[ModifiedDate])
WHEN MATCHED THEN
UPDATE SET
[Name] = s.[Name], [ModifiedDate] = s.[ModifiedDate]
WHEN NOT MATCHED BY source THEN
DELETE
;
SET IDENTITY_INSERT [Person].[PhoneNumberType] OFF;
DROP TABLE #Person_PhoneNumberType;
-- End data of table: [Person].[PhoneNumberType] --
END
GO
Scenario #4 (Full update, excluding Delete)
For Scenario 4 you must just omit lines 37-38 in order not to delete rows (added by someone manually in the target database, but that are not present in the source).
CREATE PROCEDURE [data].[Populate_Person_PhoneNumberType]
AS
BEGIN
/*
Table's data: [Person].[PhoneNumberType]
Data Source: [DEV19].[AdventureWorks2014]
Created on: 18/10/2019 15:06:49
Scripted by: DEV19\Administrator
Generated by Data Script Writer - ver. 2.0.0.0
*/
PRINT 'Populating data into [Person].[PhoneNumberType]';
IF OBJECT_ID('tempdb.dbo.#Person_PhoneNumberType') IS NOT NULL DROP TABLE #Person_PhoneNumberType;
SELECT * INTO #Person_PhoneNumberType FROM [Person].[PhoneNumberType] WHERE 0=1;
SET IDENTITY_INSERT #Person_PhoneNumberType ON;
INSERT INTO #Person_PhoneNumberType
([PhoneNumberTypeID], [Name], [ModifiedDate])
SELECT CAST([PhoneNumberTypeID] AS int) AS [PhoneNumberTypeID], [Name], [ModifiedDate] FROM
(VALUES
(1, 'Cell', '20171213 13:19:22.273')
, (2, 'Home', '20171213 13:19:22.273')
, (3, 'Work', '20171213 13:19:22.273')
) as v ([PhoneNumberTypeID], [Name], [ModifiedDate]);
SET IDENTITY_INSERT #Person_PhoneNumberType OFF;
SET IDENTITY_INSERT [Person].[PhoneNumberType] ON;
WITH cte_data as (SELECT CAST([PhoneNumberTypeID] AS int) AS [PhoneNumberTypeID], [Name], [ModifiedDate] FROM [#Person_PhoneNumberType])
MERGE [Person].[PhoneNumberType] as t
USING cte_data as s
ON t.[PhoneNumberTypeID] = s.[PhoneNumberTypeID]
WHEN NOT MATCHED BY target THEN
INSERT ([PhoneNumberTypeID], [Name], [ModifiedDate])
VALUES (s.[PhoneNumberTypeID], s.[Name], s.[ModifiedDate])
WHEN MATCHED THEN
UPDATE SET
[Name] = s.[Name], [ModifiedDate] = s.[ModifiedDate]
;
SET IDENTITY_INSERT [Person].[PhoneNumberType] OFF;
DROP TABLE #Person_PhoneNumberType;
-- End data of table: [Person].[PhoneNumberType] --
END
GO
Cool. Merge statement is not easy to remember and also adopting it for dozens of tables is a time-consuming process. Furthermore, to standardise the code for all tables – would be perfect to use a tool to script the data.
Thankfully, you are not alone here. You have two options.
Scripting master data
In this post, I want to show you two tools which can help:
- Data Script Writer (Desktop Application for Windows)
- Generate SQL Merge (T-SQL Stored Procedure)
Data Script Writer (desktop app)
This is open-source, simple Desktop application for Windows which allows you to connect to your database, list of tables, select the ones you are interested in and with one button – script ALL the data to files.
Let’s familiar with the process:
- Run the app and connect to your server and select database:
Data Script Writer (Desktop App) – Connect to Server
- Once hit CONNECT the App will load the list of all tables with information of the number of rows per each table.
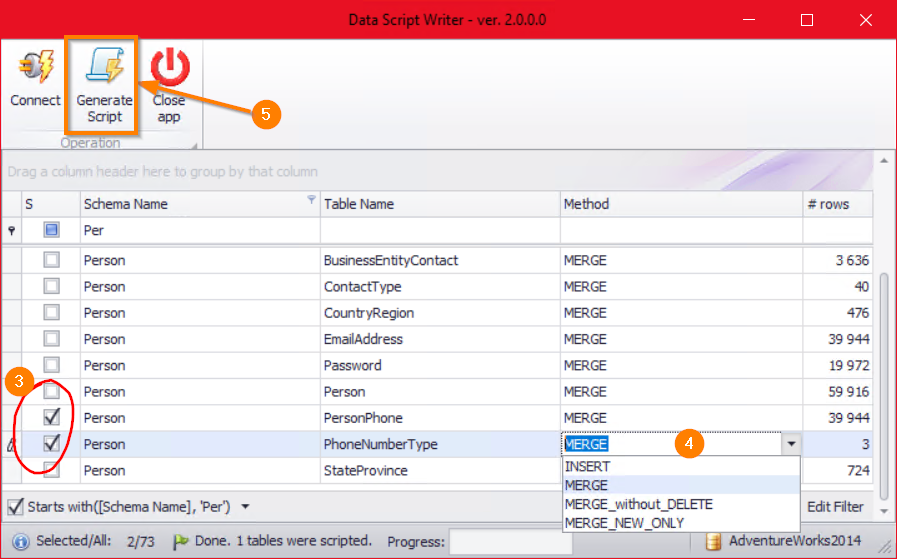
Data Script Writer – select tables and script method
- Check all tables you want to script.
- Optionally you can select a method of pushing the data into the target:
a) INSERT (see: scenario 2 above)
b) MERGE (see: scenario 3 above)
c) MERGE without DELETE (see: scenario 4 above)
d) MERGE NEW ONLY (see: scenario 1 above) - Click “Generate script” to do the things.
The last step is to put all these scripts into our SSDT database project.

“Show All Files” button
To do this – follow the steps:
- Copy these scripts to the location of the database project. (e.g.: Data/Stored Procedure)
- Select the database node.
- Switch on the option “Show all files” to be able to see hidden files (not attached to the project)
- Select all required files and click “”
- Check everything is ok by building project
The application is available to download here (git repo): Data Script Writer.
Generate SQL Merge (script)
It’s an open-source script that helps you generate MERGE statement with static data.
Firstly, you must install the script on the server. Installation is trivial:
Simply execute the script, which will install it in “master” database as a system procedure (making it executable within user databases).
As I’m a PowerShell enthusiast, I have created a simple script that does this for you:
$url = 'https://raw.githubusercontent.com/readyroll/generate-sql-merge/master/master.dbo.sp_generate_merge.sql';
$temp = [System.IO.Path]::GetTempPath()
$outputfile = "$temp\sp_generate_merge.sql"
Write-Host "Downloading script $outputfile ..."
Invoke-WebRequest -Uri $url -OutFile $outputfile
$script = Get-Content $outputfile -Raw
# Exec script
$databaseServer = 'localhost'
$server = New-Object Microsoft.SqlServer.Management.Smo.Server($databaseServer)
$server.ConnectionContext.ConnectionString = $connectionString
$sql = [IO.File]::ReadAllText($outputfile)
$batches = $sql -split "GO\r\n"
$VerbosePreference = 'Continue'
Write-Host "Batches prepared to be executed: $($batches.Count)"
$server.ConnectionContext.BeginTransaction()
$batches | ForEach-Object {
try
{
$r = $server.ConnectionContext.ExecuteNonQuery($_)
}
catch
{
$server.ConnectionContext.RollBackTransaction()
Write-Warning -Message $_
throw
}
}
if ($server.ConnectionContext.TransactionDepth -gt 0) {
$server.ConnectionContext.CommitTransaction()
Write-Host "Instalattion completed successfully."
}
It’s worth to mention that the script can be stored in [master] database to be used from any user database context.
--Mark the proc as a system object to allow it to be called transparently from other databases EXEC sp_MS_marksystemobject sp_generate_merge GO
How to use it once installed? Let’s take the table [PhoneNumberType] from [AdventureWorks] database as an example:
EXEC AdventureWorks.dbo.sp_generate_merge @schema = 'Person', @table_name ='AddressType';
As a result, you’ll get the following script:
USE [AdventureWorks2014] GO --MERGE generated by 'sp_generate_merge' stored procedure --Originally by Vyas (http://vyaskn.tripod.com/code): sp_generate_inserts (build 22) --Adapted for SQL Server 2008+ by Daniel Nolan (https://twitter.com/dnlnln) SET NOCOUNT ON SET IDENTITY_INSERT [Person].[PhoneNumberType] ON MERGE INTO [Person].[PhoneNumberType] AS [Target] USING (VALUES (1,N'Cell','2017-12-13T13:19:22.273') ,(2,N'Home','2017-12-13T13:19:22.273') ,(3,N'Work','2017-12-13T13:19:22.273') ) AS [Source] ([PhoneNumberTypeID],[Name],[ModifiedDate]) ON ([Target].[PhoneNumberTypeID] = [Source].[PhoneNumberTypeID]) WHEN MATCHED AND ( NULLIF([Source].[Name], [Target].[Name]) IS NOT NULL OR NULLIF([Target].[Name], [Source].[Name]) IS NOT NULL OR NULLIF([Source].[ModifiedDate], [Target].[ModifiedDate]) IS NOT NULL OR NULLIF([Target].[ModifiedDate], [Source].[ModifiedDate]) IS NOT NULL) THEN UPDATE SET [Target].[Name] = [Source].[Name], [Target].[ModifiedDate] = [Source].[ModifiedDate] WHEN NOT MATCHED BY TARGET THEN INSERT([PhoneNumberTypeID],[Name],[ModifiedDate]) VALUES([Source].[PhoneNumberTypeID],[Source].[Name],[Source].[ModifiedDate]) WHEN NOT MATCHED BY SOURCE THEN DELETE; DECLARE @mergeError int , @mergeCount int SELECT @mergeError = @@ERROR, @mergeCount = @@ROWCOUNT IF @mergeError != 0 BEGIN PRINT 'ERROR OCCURRED IN MERGE FOR [Person].[PhoneNumberType]. Rows affected: ' + CAST(@mergeCount AS VARCHAR(100)); -- SQL should always return zero rows affected END ELSE BEGIN PRINT '[Person].[PhoneNumberType] rows affected by MERGE: ' + CAST(@mergeCount AS VARCHAR(100)); END GO SET IDENTITY_INSERT [Person].[PhoneNumberType] OFF SET NOCOUNT OFF GO
There is more option to be chosen, but it’s not my goal to present you all of them. One the website you find out all details.
When updating the tables?
The best moment to do that is just after deployment the changes. That means: post-deployment script.
The first, easiest way, is to only append the script file to the deployment script:
:r ..\Data\Person.PhoneNumberType.sql
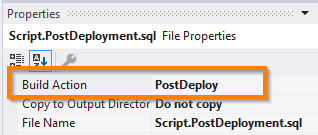
Required property of Post-Deployment file
A drawback of that approach is that the whole script appears in there whenever deploying the database. And even worse: the whole script won’t be parsed like all other scripts which are being defined as post-deployment.
My recommended method
I would like to suggest one particular approach to address that case. I have applied it many times in multiple projects and it just works.
Let’s take a look at the code. We require:
- Separate schema (e.g. “data”) – optionally
- Script inserting the data wrapped up in Stored Procedure
- One “principal” stored procedure which calls all others.
- Post-deployment script when you have only one line of code – execute the “principal” procedure
Does that make sense? I hope so. To make sure that you understand it better – have a look the following pic:

All you need is… these files
To convince you more to this approach, let me list all its advantages:
- The stored procedures are part of the database project.
- They will be validated and compiled, thus you avoid potential errors with uncontrolled code
- The changes to the SP appears in output script only when something changes.
It’s easier to review the script before a run as it doesn’t contain unnecessary code - Having separate schema – you can control who has access to the SPs to protect against accidental executions
- Having “principal” SP – you can control what and when will be executed, means populated.
- In Post-deployment script – there is only one line of code which never is changed.
It is important as this script is not built, so you must trust that it contains faultless code.
For me – it’s much more than enough reasons to apply this methodology.
icon-github I populated a small table with data in this post. If you want to see entire code – check that repo on GitHub: ssdt-demo
Summary
Let’s wrap up what we learned today. I do distinguish a few scenarios of updating the data in the target server. Perhaps not all of them is necessary for your scenario, but it works for me, that’s why I decided to share. The following table allows you to understand them better:
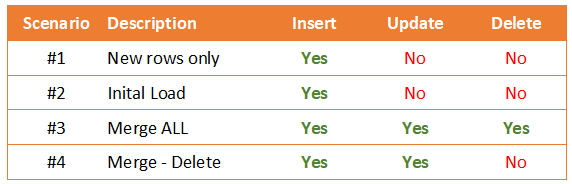
How does your solution look like?
I’m not trying to tell you that my solution is the best (even if I think that 😉 )
You don’t have to like it, maybe it just would not work for you, or you have particular requirements. Each project is specific, although 90% of them can use the examples presented above.
What is your experience with this area?
Maybe you know a better way to do the things?
Do you have something to add here?
Please do and leave a comment.
About author

You might also like

#TSQL2sDay – How SQLPackage.exe can spoil your deployment
Today, I’d like to describe briefly one thing with SQLPackage.exe. I know… It’s not precisely related to PowerShell (this week topic), but… you can use PowerShell to run it (and

Deployment of Microsoft SQL database with Azure DevOps
Hello, data folks! I have published several articles about databases and their maintenance in SSDT project on the blog. One of the posts explained step by step how to import

{kind=link}
Tokenization of database project in SSDT
SSDT project has something we call Variables. On the Internet (posts, forums) they also are known as placeholders or tokens, especially when talking in a deployment/CI/CD/DevOps context. Variables can be found for
Leave a Reply


6 Comments
Sufian
December 16, 12:06Hi Kamil-
Thanks for this very helpful and detailed blog post.
One question:
How do you manage the update/DML scripts which have already been executed on production server?
Do you archive them inside SQL project?
We want to keep history of all the scripts that were executed on production; but we also need to make sure that any previous scripts are not executed again accidentally.
I am thinking of creating folder for PRE and POST scripts in Visual Studio and maintaining the scripts for each day.
What are your thoughts on this?
Kamil Nowinski
December 23, 22:02Hello Sufian. Thanks for your comment here.
I guess that the question is not directly related to this post.
sqlpackage.exe is responsible for creating a “changes script” during the deployment process (release pipeline). I explain this a bit deeper in my latest video: https://azureplayer.net/2019/12/deployment-of-microsoft-sql-database-with-azure-devops/
The second part of your comment suggests me that you have (instead of SSDT or with SSDT as a hybrid model) some extra scripts which need to be executed before/after the deployment. But that kind of approach is used in specific scenarios and I’d like to ensure that you understand the concept of DACPAC and its publication to a target database.
If so, to protect the deployment process against executing the same scripts multiple times – you must provide an additional table with states per each script executing in pre/post-deployment. Having that you must also provide the logic which inserts appropriate info to the table and verify each script before run it. Logic might be provided as Stored Procedures or PowerShell script.
I don’t have any good example of code for that case, but I will prepare a post or video about it soon.
Antonio
May 21, 14:44If you prefer a workflow where you execute scripts once and not again, you may want to look at DbUp library. ( disclaimer : I’m not associated w/DbUp ) https://dbup.readthedocs.io/en/latest/
We used it in a scenario where we could not use SSDT (target was a Postgres DB) and it worked just ok. It maintains a table in the target db of the scripts that have already been executed. In our case we wrote a simple command line app that uses this library. As Kamil mentions, if you are using SQL server maybe implementing a combination of both approaches is the way to go.
Tim
June 30, 15:08If you got many post deploy data modification procedures that populates data and/or they are heavy to run them each deployment you may want to think into some optimizations. For example, we may calculate hash values based on definition of old version of population procs in pre-deploy script, put the value into a session context, and read it in post-deploy script. Execute population procs only if hash changed…
khaja
August 22, 15:47Hi Kamil,
Is there a way to load data from a csv, excel or text file to the database using the SSDT seeding process.
For now i am in a way seeding data using the merge scripts but there is an ask in my project to see if we can load data using a file instead of a merge script.
Thanks,
Khaja
NullReference_Object
March 24, 13:26Very nice and interesting post! Have couple questions here, and would like your insights.
how do you determine which rows are to insert/update/delete?
Lets say,
1. To start with the same script is executed dev, stage and prod.
During an hotfix, the prod has been updated, in other ways, not through a pipeline or this master script, but some incremental data updates separately. Perhaps, might be the same reason as you mentioned (i.e. data could change accidentally by developers, external system (when should not) or undiscovered process). Or the dev has ongoing changes while prod has been updating through hotfix patches.
1. what strategy to apply hotfix vs ongoing differences?
2. how to identify the data in git master data repo vs prod database vs dev database, and identify which one to consider?
(Please note that we are dealing with databases, and sometimes not following proper process or having access to DBs to update the data, or the data modifications through undiscovered process, we cannot loose them). So have to find a strategy to apply which version is correct before sync process. Do you have any insights in here? Like how to arrive at a decision matrix which will tell us below? For e.g. for same table if a hotfix is deployed for one column (Column1), and for ongoing changes for Column2 in dev. How to come to this decision matrix? Can this be done completely automated? or do we need to identify the differences and discuss with team and come to a decision. Thanks for your time.
for e.g.
Source Env | Target Env | Table Name | Column Name | Decision
=======================================================================
Repo master branch | Dev Env | dbo.abc | dbo.Column1 | Update Target with Source value.
Repo master branch | Dev Env | dbo.abc | dbo.Column2 | Update Source with Target value. Probably ongoing changes in dev?
=======================================================================
3. How to sync data across different environments? like from prod master data to stage or prod master data to dev?