
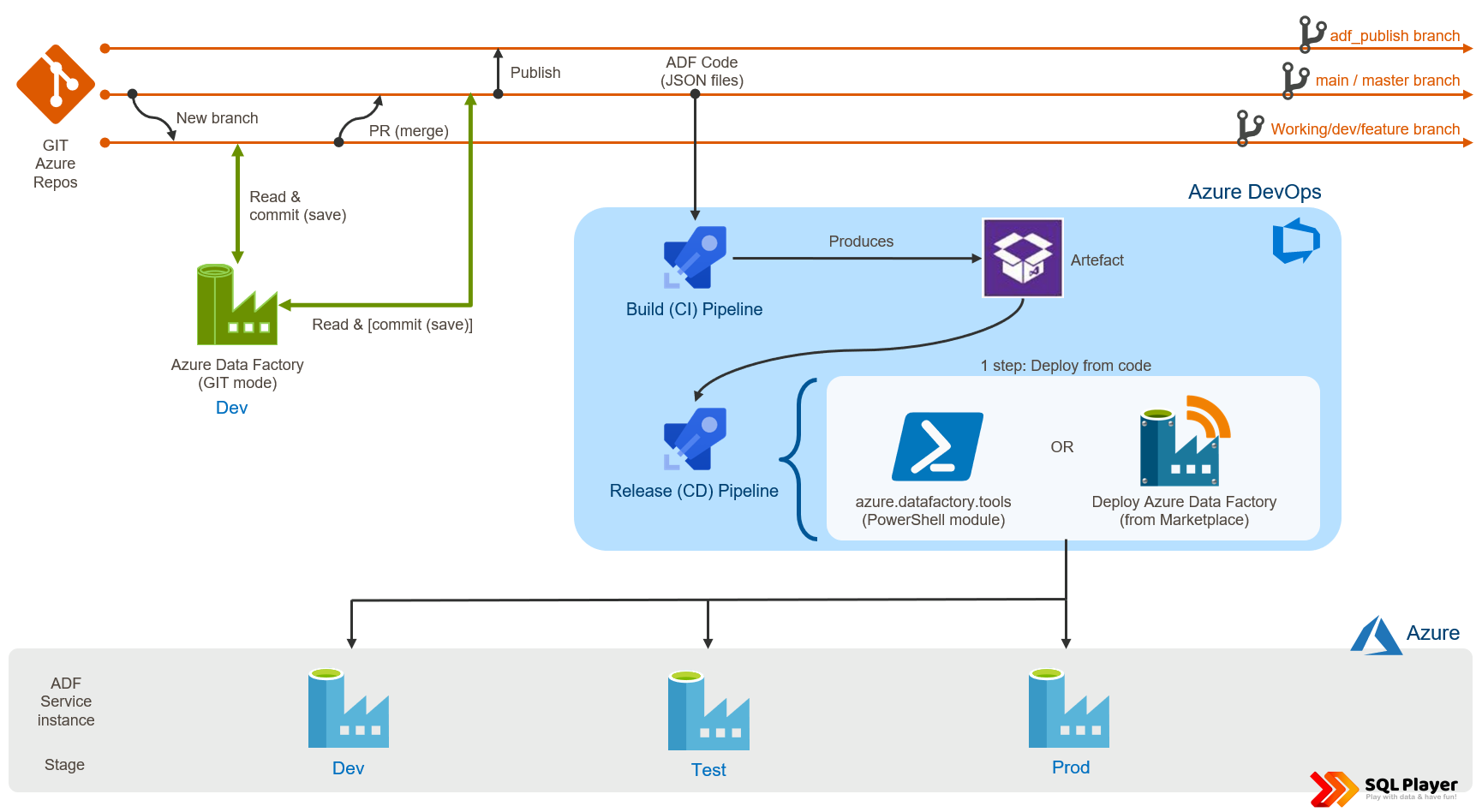
Two methods of deployment Azure Data Factory
Azure Data Factory is a fantastic tool which allows you to orchestrate ETL/ELT processes at scale. This post is NOT about what Azure Data Factory is, neither how to use, build and manage pipelines, datasets, linked services and other objects in ADF. This post is completely focused on the topic of deployment (aka publish) Azure Data Factory from code to the instance (service) in the cloud.
Developing pipelines in ADF
I’ve been working with ADF since 2018. At the time, the whole ADFv2 was in preview and the product was (and still is) fastly develop by MS Team (kudos to Mark Kromer and his team). Today, ADF is a pretty mature product and offers a lot of useful features, including Global Parameters, Mapping Data Flow, GIT integration and much more. We are focusing here on governance the code of ADF and how to deploy it from a code repository to the service, hence mentioning the integration with GIT was on purpose.
While working with ADF UI by the browser may not be a preferable way for many (there is no Visual Studio support for ADFv2 as it was for v1 and Microsoft is not planning to do so in nearest time), the UI is better and better and doesn’t cause much trouble when building pipelines. Also, as long as you develop the solution only in one instance (let’s name it DEV environment), you will not spot any issue or problem. Until you try to promote and deploy the code of ADF to further environment (or stage – using naming nomenclature from Azure DevOps).
Two approaches to deploying ADF
I used ADF in a few organisations, so far, for the last few years.
In most cases, we used an approach of deploying ADF directly from code, from a branch in GIT repository. I knew that Microsoft recommends only one way of CI/CD for Data Factory. The whole concept and details are described here: Continuous integration and delivery in Azure Data Factory.
Unfortunately, I found this way of little use and hard to use. Hence, then I realised: hey, if I feel like that and used a different publish approach a few times – maybe the others also have similar problems or just prefer his own approach of doing this? I did a quick poll on Twitter asking people what kind of method they use:
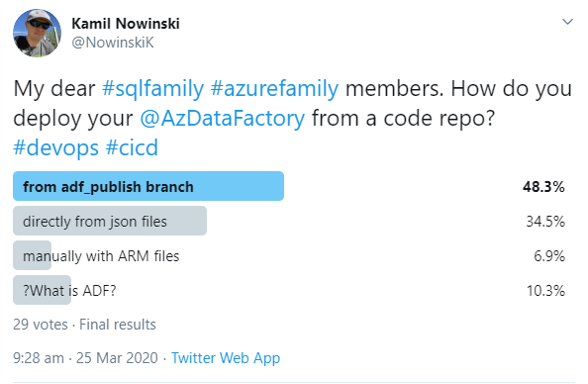
Twitter Poll: Who uses what?
Turned out that two-third of people use Microsoft’s deployment way, according to their answers on that poll (including few people who publish the code manually). In 1/3 cases people prefer to deploy directly from code. You may ask: what’re the differences? What characterizes both methods? Which one is better?
Before I start answering these questions, let me present both methods of publishing.
#1 Microsoft approach (ARM template)
In both approaches, you must set up GIT integration to assign your ADF service to the selected repository. If you are not sure how to achieve that – I described it here: Setting up Code Repository for Azure Data Factory v2. As a developer, you can work with your own branch and can switch ADF between multiple branches (including master/main). How this is possible? It’s because having one ADF instance you can switch between two modes: GIT integrated (for development purposes) and real instance.
However, if you want to publish the changes (or new version) to another environment (or instance) – you must Publish the changes first. This performs to actions:
- Publishes the code from a developer version of code to real ADF instance. This can be done only from one branch: “collaboration” branch (“master” by default)
- Creates or updates ARM Template files into “adf_publish” branch. This branch will be used as a source for deployment.

Deployment (#1 approach): Microsoft method (ARM Template)
Then you can build your own CI/CD process for deployment of ADF, using Azure DevOps, for instance. I don’t want to dig deeper about how to deploy ADF with this approach as I already described it in the post: Deployment of Azure Data Factory with Azure DevOps.
Why many people (including me) do not like this approach?
- Semi-manual process, as at some point someone has to hit “Publish” button
- Full ADF (all artefacts) can be deployed only (no selective deployment)
- Limitation to one publish branch only (thankfully, you can name it now)
- Parametrize elements exposed within the ARM Template Parameter
- Restriction of 256 parameters maximum
- Building a release pipeline is not an easy thing
- Will not delete any existing ADF objects in the target instance, when the object has been deleted from the source ADF
- Must use a few tasks in Release Pipeline (Azure DevOps) to deploy ADF (including PowerShell script)
I will discuss the above things more precisely below.
I’m not saying that Microsoft’s approach is wrong. You may prefer that way. It may work for you.
However, let’s have a look at how others are doing this:
#2 Custom approach (JSON files, via REST API)
There is another approach in opposite to ARM templates located in ‘ADF_Publish’ branch. Many companies leverage that workaround and it works great. In this scenario, you don’t have to Publish the changes to update ARM Template. With this approach, we can fully automate CI/CD process as collaboration branch will be our source for deployment. This is the reason why the approach is also known as (direct) deployment from code (JSON files). In all branches, ADF is stored as multiple JSON files (one file per object), whereas in ADF_Publish branch – ADF is kept as ARM (Azure Resource Manager) Template file(s).
Deployment (#2 approach): Directly from code method (JSON files)
Why some people prefer this approach?
- It’s much more natural and similar to managing the code of other applications
- Eliminates enforcement of using only one (
adf_publish) branch (helpful if the company’s branches policy is much complex) - You can parameterize any single property and artefact of the Data Factory
- Selectively deploy a subset of artefacts is possible
- Only one task in Release pipeline (Azure DevOps) covers all the needs of deploying ADF from code (more details below)
What both have in common?
In both cases, you must manage ADF triggers properly. Before deployment of any (active) trigger onto target ADF, it must be stopped, then deploy everything and start triggers again. This requires additional steps in a Release pipeline in order to do so. Microsoft offers PowerShell script to start/stop triggers as pre/post-deployment activity.
Make your life easy
Back in June 2020, I decided to write a brand new PowerShell module to help all of us when publishing the whole Azure Data Factory code from your (master) branch or directly from your local machine. It’s called azure.datafactory.tools, is an open-source and completely free module which you can download from PowerShell Gallery.
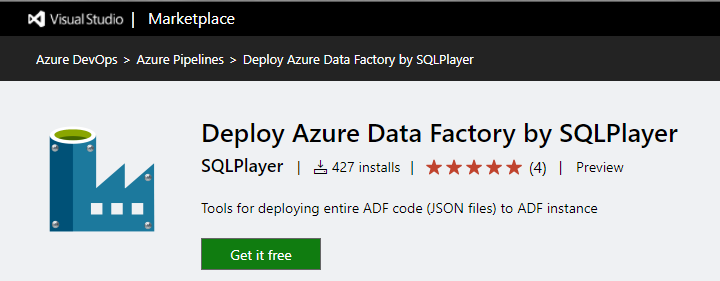
Deploy Azure Data Factory extension to Azure DevOps in Microsoft Marketplace
A few months later, on top of that, I created an extension to VSTS/Azure DevOps which allows you to do exactly the same things as a (one!) task in Release Pipeline. The task is called “Deploy Azure Data Factory by SQLPlayer” and can be found in Microsoft Marketplace.
More information on this page: SQLPlayer.net/adftools
Hash tag: #adftools
The rest of this post takes you through the aspects of using the approach of deployment ADF from code. Although you can write whole PowerShell code to deploy ADF on your own, I deeply recommend the usage either azure.datafactory.tools module or task mentioned above. It doesn’t make sense to reinvent the wheel, does it? Both tools will be called #adftools in the post below.
Deploying objects in an appropriate order
This problem doesn’t exist in Microsoft approach while deploying from ARM Template, you just don’t have to worried about it. However, deploying ADF objects (artefacts) one by one, you must care for dependencies between all of them. This is one of the most difficult things when you want to deploy ADF from code using RestAPI and your own script. #adftools does it for you automatically and it does it very well.
Publish options
There is only one method (or task) to publish ADF from code in #adftools. However, you have full control over the behaviour of the publication process. Publication parameters are used for this, which allow achieving all the below-mentioned goals. That’s the biggest and most meaningful advantage of the #adftools.
Stop/start triggers
This issue is relevant for both approaches as always you must stop a trigger in order to update it. ARM deployment will not help you here. Therefore, you must take care of this before starting the deployment. In #adftools, there is a parameter (publish option) StopStartTriggers. It allows you to decide. It stops ALL existing and `Started` (Enabled) triggers. Generally, you should use TRUE (default) if you want to avoid troubles.
However, if you choose FALSE – you must accept that process WILL NOT touch triggers. You can still do it for yourself in pre or post-deployment script.
Selective deployment
There are many different ways of how people are working with ADF in terms of its deployment. Some want to deploy only selected objects. That option is not available with Microsoft approach via ARM Template, it’s unsupported feature:
By design, Data Factory doesn’t allow cherry-picking of commits or selective publishing of resources. Publishes will include all changes made in the data factory.
Data factory entities depend on each other. For example, triggers depend on pipelines, and pipelines depend on datasets and other pipelines. Selective publishing of a subset of resources could lead to unexpected behaviours and errors.
On rare occasions when you need selective publishing, consider using a hotfix. For more information, see Hotfix production environment.
Although I agree that the concept is not easy, IMHO ADF Team exaggerates. As one of the options comes with #adftools is selective deployment. You can define a list of ADF artefacts you want to deploy by specifying them precisely by name (Includes collection), or (as an opposite), specifying which objects you do NOT want to deploy (Excludes collection). This is a very useful feature but would be a bit useless when you have to add each object to the list every time when new is created.
Therefore, you can use the capability of defining objects by wildcards in its names or types. Furthermore, you can organise your objects in folders (in ADF) and selecting (or deselecting) them using name of folder(s) only. That will include or exclude all objects belong to the folder(s).
The syntax for pointing objects is: type.name@folder, where folder is optional.
Look at the following examples:
trigger.* dataset.DS_* *.PL_*@test* linkedService.???KeyVault* pipeline.ScdType[123] trigger.*@testFolder
Parametrisation / Custom parameters
ARM Templates can be parametrized. Files created by ADF when you hit Publish button in UI have got parameters as well. The more objects you have in your ADF the more parameters will land in ARM Template. It is defined in the parameterization template of ADF which properties of which objects are being exposed. The parameterization template is in JSON format and hasn’t user-friendly syntax.
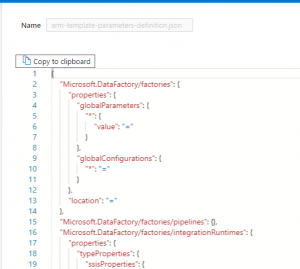 Today, Microsoft shares example of that file for multiple objects, however working with the file is not one of the most pleasant things.
Today, Microsoft shares example of that file for multiple objects, however working with the file is not one of the most pleasant things.
So, you may say: let’s leave default content and do not bother to modify the file? Sure. Yes, you can. In most cases, it would work.
Unfortunately, sometimes you may be forced to do it:
- You have too many objects in ADF and amount of parameters exceeds 256
- Some of the properties you want to change during the CI/CD process are not parameterized by default
In such cases, use the custom parameter file and remove properties that don’t need parameterization or extent it by adding the right section(s) for selected objects and properties. Do follow the instructions on Microsoft documentation to discover how “easy” it is.
Sometimes, instead of adding parameters to the template, you can slightly change ADF by adding global parameter(s) and leverage it wherever needed. That minimises the efforts, still keeping the solution clear and understandable.
Using #adftools, you will not even bother with parameterization template. Because that “other” approach uses JSON files as a source of deployment. In that scenario, we don’t know and don’t care what’s in ‘adf_publish’ branch, because we do not use it. Our source is main, master or another collaboration branch, which contains the version of ADF ready to deploy.
How to override parameters then?
It’s very easy. #adftools has a build-in mechanism to replace the properties with the indicated values (CSV file). You must create a configuration file (CSV or JSON format) and define all properties of objects which value need to be replaced (optionally they can be added or removed). The good thing is you can define an absolute minimum set of objects. Another good thing is: you can use wildcards to specify multiple objects if they have recurring value pattern.
An example of the file may looks as follow:
type,name,path,value # As usual - this line only update value for connectionString: linkedService,BlobSampleData,typeProperties.connectionString,"DefaultEndpointsProtocol=https;AccountName=sqlplayer2019;EndpointSuffix=core.windows.net;" # MINUS means the desired action is to REMOVE encryptedCredential: linkedService,BlobSampleData,-typeProperties.encryptedCredential, # PLUS means the desired action is to ADD new property with associated value: linkedService,BlobSampleData,+typeProperties.accountKey,"$($Env:VARIABLE)" factory,BigFactorySample2,"$.properties.globalParameters.'Env-Code'.value","PROD" # Multiple following configurations for many files: dataset,DS_SQL_*,properties.xyz,ABC
You can decide to keep one config file per environment or create only one file and govern all values in Azure DevOps Variables. Both ways are OK, just remember to NOT keep sensitive information (credentials, keys, secrets, passwords, connection strings which contain password, etc) in plain text in the config file. For such properties, put placeholders like $Env:VariableName and keep values securely in Azure DevOps Variables or read them from Azure Key Vault prior.
More information about config files in the documentation of azure.datafactory.tools PowerShell module.
Dropping objects not existing in the source any longer
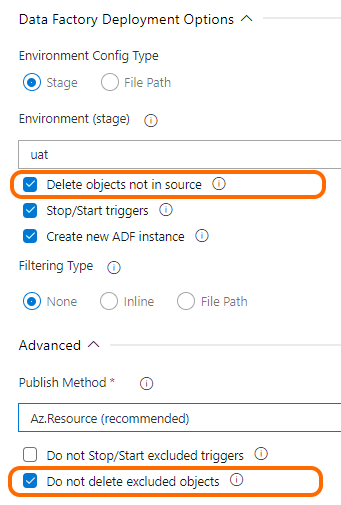
Publish options in a Release pipeline task
This option simply does not exist in Microsoft approach. Publishes will include all changes made in the data factory, albeit it will NOT delete any objects (dataset, pipeline, etc.) removed from ADF by a developer in Git mode.
Therefore, when you delete any object in ADF – it will disappear from code repo, but still is present in ADF service, even after deployment. You must delete these objects manually. If you leave such a mess for some time, you may find yourself in a situation where many objects need to be removed. Deleting objects in ADF requires taking all dependencies between objects into consideration to be able to delete them in the correct order. This may make this task time-consuming and not easy.
Not to mention that the publishing process should be fully automated, without manual interference and rummaging through ADF objects (especially in production).
Hence, it’s another advantage of using #adftools rather than deployment ADF from adf_publish branch and ARM Template.
Obviously, it’s only an option and by default is disabled.
In the PowerShell module, there are two options in PublishOption class:
– DeleteNotInSource – Indicates whether the deployment process should removing objects not existing in the source (code)
– DoNotDeleteExcludedObjects – Specifies whether excluded objects can be removed. Applies when DeleteNotInSource is set to True only.
Both have their counterparts in Task extension to Azure DevOps (see picture on the right).
As I mentioned above, #adftools offers filtering objects intended for deployment by using ‘Includes’ or ‘Excludes’ collection, or Filtering options in DevOps Task.
In that case, is worth to remember an excluded object can be deleted only if flag `DoNotDeleteExcludedObjects` = false.
This situation could cause an error when a trigger has not been disabled prior and is being deleted.
When flag `DoNotDeleteExcludedObjects` = true, nothing will happen to exclude objects.
This option gives you a flexibility of deleting objects in the target, but still not touching objects from ‘other’ group.
Recap
Let’s summarize what we’ve learnt in this post. All this information can be very confusing, therefore quick overview might be helpful here. Let me compare both deployment methods in the table for better understanding.
| The method recommended by Microsoft | Deployment from code | |
|---|---|---|
| Deployment method | ARM Template | RestAPI / PowerShell |
| Source location | ADF_publish branch. Only one per ADF |
Master or any other branch. Multiple branches possible |
| Source files | ARM Template files | Artefact JSON files |
| Custom parameter syntax | arm-template-parameters-definition.json | Not required |
| Input parameters | ARMTemplateParametersForFactory.json | Config file or files CSV or JSON format |
| Number of parameters | Limited to 256 | No limit |
| Selective deployment | Unsupported | Available by filtering |
| Dropping objects not existing in the source | Unsupported | Available as option |
| Visible in Deployments (Resource Group) | Yes | No |
I hope this post helped you to understand what kind of alternatives you have when it comes to publishing Azure Data Factory and you understand the differences. It’s up to you which method you’ll choose, probably based on your preferences and skills available in your team.
Good luck!
Useful links
Microsoft documentation: Continuous integration and delivery in Azure Data Factory
#adftools – Depends on your preferences, you can use:
– azure.datafactory.tools PowerShell module: GitHub code & doc | PowerShell Gallery
– or extension to VSTS/Azure DevOps: Deploy Azure Data Factory by SQLPlayer.
Who mentioned the #adftools
Azure Data Factory CI/CD with GitHub and Azure Pipelines
CI/CD for Azure Data Factory: Create a YAML deployment pipeline
Using Azure DevOps CI CD to Deploy Azure Data Factory Environments
Continuous Integration and Continuous Delivery in Azure Data Factory V2 using Powershell: Part 1
About author

You might also like

{kind=link}
Last week reading (2018-01-14)
The top 7 business benefits of establishing DevOps in your organization No comments, find and understand the benefits. Columnstore Indexes – part 116 (“Partitioning Specifics”) What do you need to
Last week reading (2017-12-17)
How Can I Become A Microsoft MVP? Many people ask how to achieve the title, so Kevin Kline [T] answers. Forget, it’s not a recipe – just do what you
Last week reading (2018-09-30)
Entire last week was dimmed by MsIgnite, hence take a look at videos from that conference: Microsoft Ignite 2018 Some sessions recorded and available over there. CosmosDB at Ignite 2018


25 Comments
Michal Pawlikowski
January 16, 14:25Good work!
Kamil Nowinski
February 04, 22:41Thank you, Michal!
Azure Data Factory Deployment Methods – Curated SQL
January 18, 13:10[…] Kamil Nowinski contrasts two methods for deploying Azure Data Factory pipelines: […]
Automated Testing of Azure Data Factory Pipelines – Side Quests
February 08, 19:09[…] Azure Data Factory: We had many discussions about the topic, but in the end chose to use an extension build by Kamil Nowinski in stead of the Microsoft approach. The are many quality of life improvements in this […]
Francesco Milano
March 30, 10:32Great post Kamil,
going to give it a shot!
rana
July 08, 04:28Hello, Beautiful post. I have recently done few changes in the pipeline, but when i trigger the pipeline manually, the old pipeline which i modified is been executing, this is been observed in pipeline runs. can you help me how can overcome this issue ?
Kamil Nowinski
July 19, 07:48In which mode do you run the pipeline manually? Live or DEV? I suspect that you’re running in DEV mode, based on some specific (maybe old) version of code from GIT. Check this out.
Lukasz
August 16, 19:15Hi,
I just tried it, but I have ADO Git enabled on my environments, and I can see that everything has been deployed but only when I’m using “Live Mode”. Is it possible to deploy it to ADO Git as well to see those changes?
Kamil Nowinski
August 31, 10:45GitMode is reserved only for developers. It is not “real/live” instance of ADF, so it is NOT possible to deploy ADF code into that instance. There is no point in doing that as you can choose a branch from your GIT repo and work with that code directly from the browser. I hope it makes sense.
Ravneet
August 24, 09:22Big thanks to you, Your ADF tools are really helpful.
Kamil Nowinski
August 31, 10:41Thank you!
Skirmishes with automated deployment of Azure Data Factory | SQL Player
November 01, 20:26[…] Two methods of deployment Azure Data Factory […]
A Quest For Low-Code Architecture with Azure DataFactory – Andriy Bilous
July 26, 11:49[…] https://azureplayer.net/2021/01/two-methods-of-deployment-azure-data-factory/ […]
The Reason We Use Only One Git Repo For All Environments of an Azure Data Factory Solution – SQLServerCentral
November 01, 06:18[…] branch. If you deploy from JSON files, selective deployment is a bit easier. I like to use ADF Tools for deployment, which allows me to specify which files should be deployed, so I can do a special […]
Swapna
November 02, 18:17Hi Kamil, it’s a very useful, flexible, and straightforward method to deploy ADF, this really made our lives easy to deploy ADF, a big thanks to you.
I have a couple of questions.
how to handle the upgrades or new versions of the DevOps release task (Deploy Azure Data Factory by SQL Player)?
how would that impact our DevOps process?
Thanks
Kamil Nowinski
November 07, 15:00Thanks, Swapna.
ad.1) Azure DevOps handles that for you automatically. If you have access to it – you can check what’s the current version installed and when: https://dev.azure.com/{organisation}/_settings/extensions
ad.2) Never. There is NO breaking changes in new releases, so you don’t have to worry about that. Once this is required – new major version will be release which have to be select intentionally in a task.
Chaitanya
December 05, 12:24Hi, I just want to move my Azure data Factory from one subscription to another. We have an move option in the Data Factory home page, is that sufficient to provide the new subscription details, validate and then Move or do we need to do any other things from ADF perspective.
Kamil Nowinski
December 05, 14:02That would be sufficient from Azure Data Factory’s perspective, so yes, you can move ADF between subscriptions and/or resource groups as any other Azure components. In the first place, however, you should have GIT integration configured, so all ADF code is in the repository. Restoring ADF from repo would be much more quicker and easy.
Synapse Analytics workspace - deployment challenges | Azure Player
March 07, 07:46[…] Two methods of deployment Azure Data Factory […]
SJ
March 18, 22:01I am using the Validate and Export ARM Template task, the task executes successfully but I don’t see the ARM output folder being created in the specified repository location. The log shows all the files being validated and the ARM templates being generated and saved but nothing appears in the repository.
Any help on this is much appreciated.
Thanks
Subhrajit
January 16, 19:11I am working on a POC to deploy the ADF pipelines through the Azure DevOps pipeline. Initially I tried the Microsoft approach of doing it using the ARM template from adf_publish branch. Then I came to know about the tool ‘Deploy Azure Data Factory (#adftools)’ developed by you.
I found this tool to be very useful and flexible and thanks a ton to you for coming up with such an intuitive tool.
Now I would like to use the tool for actual development of my company’s project.
I have a few questions and would appreciate if you could clarify.
1) What kind of data is collected or stored by the tool or passed outside the organization.
2) Do the parameters and configuration data placed in the config file e.g., database server name, credentials go out of the organization or stored somewhere else?
3) Does the code of the ADF instance go out in any form and stored?
4) Is there a paid version of the tool?
Thanks again.
Kamil Nowinski
January 17, 12:10Hi Subhrajit,
Thanks for using the tool and your kind words about it.
Answering your questions I see you’re very conscious about privacy and I’m glad that you’re asking about this!
So, let me answer one by one:
ad.1) NO data is collected or stored by the tool itself. Also, the tools do not collect any data for analytics purposes.
ad.2) The data is yours! I don’t have access to it – there is NO process sending these (and any!) data out of your environment. Hence, none of these parameters are shared. The entire code is open-sourced and you can verify that.
ad.3) The code (similarly to configuration) always stays in your environment. It’s your code, parameters, configuration, and intellectual property that are taken very seriously by me. Again: The tools DO NOT share/send ANY information (files, code, configuration, running times, parameters) ANYWHERE. There is NO NEED to do that.
ad.4) No, there is no paid version of the tool. The tool is created by the community for the community. Is open source, free and will always remain free. You can use it commercially with no fees.
I hope that helps.
PS. Could you do me a favor and create this question here as well:
https://github.com/Azure-Player/azure.datafactory.tools/discussions/categories/q-a
Mahesh
April 12, 14:25Hi Kamil,
We have implemented ADF Selective deployment and its working as expected.
I have query if do you same solution for deploying selective Azure Databricks Notebooks?
Mahesh
May 01, 10:15Hi Kamil Nowinski
Is there any similar tool/extension available to selectively deploy Azure Databricks notebooks?
Kamil Nowinski
May 09, 20:08In the past (few years ago) I used azure.databricks.cicd.tools, but the tool is deprecated now.
Take a look at Databricks latest & greatest approach for deploying named: Databricks Asset Bundles.