

Deployment of Azure Data Factory with Azure DevOps
In this blog post, I will answer the question I’ve been asked many times during my speeches about Azure Data Factory Mapping Data Flow, although the method described here can be applied to Azure Data Factory in general as MDF in just another type of object in Data Factory, so it’s a part of ADF automatically and as such would be deployed with other parts.
Whenever I say Azure Data Factory in this post – I mean: Azure Data Factory v2. Forget about v1, ok?
Code Maintenance
From the very beginning, Azure Data Factory has the capability to keep the code of ADF synchronized with code repository.
In fact, when you hook up your ADF with the code repository, you’ll have two types of the instance of Data Factory:
- ADF mode (the main one) – this is a deployed version of ADF
- GIT mode – separate version of ADF which is synchronized with repo and can be used to develop new features
Two modes of ADF
Both of these modes work differently. At the beginning after ADF creation, you have access only to “Data Factory” version. I described how to set up the code repository for newly-created or existing Data Factory in the post here: Setting up Code Repository for Azure Data Factory v2. I would recommend to set up a repo for ADF as soon as the new instance is created. Your life as a developer (also as whole developer team) would be much easier.
Working in “Data Factory” mode you can trigger any pipeline, so that will be visible in monitoring tool for everyone and available later on. When changing the code with UI, you can publish only fully validated code (whole ADF across all objects is being validated). This instance (code) is shared for everyone who has access to it. That also means you can lose your changes being overridden by someone else or you potentially could override someone’s changes when publishing the code as the latest one.
In Git repository mode (e.g. “Azure DevOps GIT”) you will be work on your own branch, so no changes lose risk, but also your development experience with ADF will be much pleasant. You don’t have to finish your work to be able to save the changes (yes – saving, not publishing), having the opportunity to test your version in debug mode. Bear in mind that in this mode you can not run your version of the pipeline through a trigger. The triggers run only deployed (“Data Factory”) version of pipelines. You would get the following warning once you try:
ADF code is JSON
Before we go further, we must understand how the code of ADF does look like. Generally speaking, the code is kept in JSON format. The code reflecting the ADF in the repository is divided into folders and files. Folders represent object types, and each file represents one object in the ADF. So, under the main folder, you will see such subfolders:
- dataflow
- dataset
- integrationRuntime
- linkedService
- pipeline
- trigger
Some of these folders might not exist when objects of particular types are not used in Azure Data Factory. Here is an example:

Azure Data Factory and its JSON files in GIT code repository
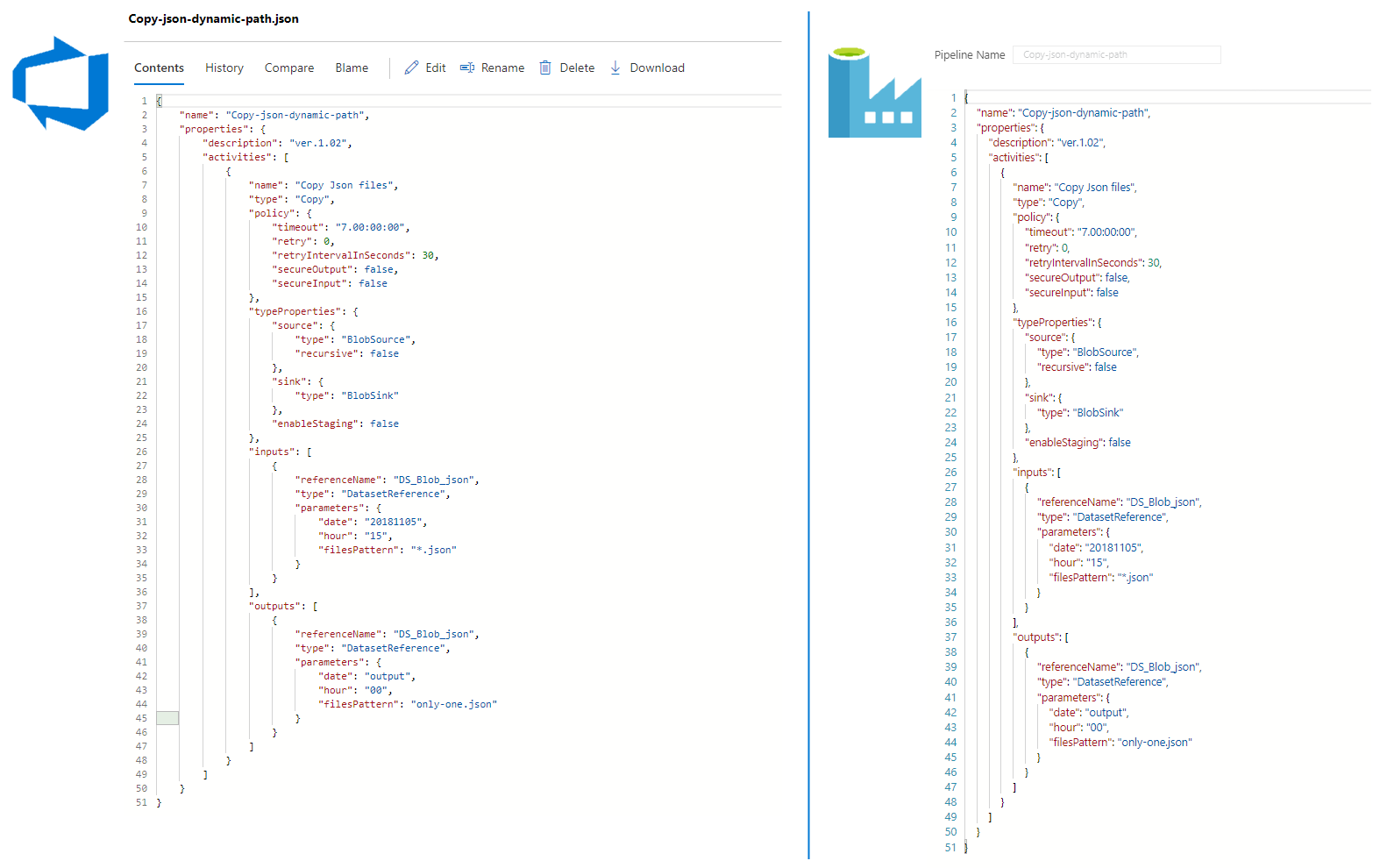
Comparison of code seen in ADF and GIT
If we look inside the selected file – we will see exactly the same code that can be seen by working with Authoring of ADF (“Code” button in the right-upper corner of the screen when editing the object):
As you rightly notice – this approach is significantly different from the ARM Templates file structure, where we have everything in one, big file. Although it is possible to use these files for the deployment of ADF (Microsoft describes this here), I personally do not recommend this method.
What’s all the noise about?
You might be familiar with operations Import/Export ARM Template available from ADF. If you are not – nothing lost. If you are – good. Nevertheless, we will not use this option. Our goal is to automate the deployment process. No clicking, therefore, comes into play. We are going to use the best practice of working way with code repository with ADF, recommended by Microsoft.
Before we started working with ADF+GIT method – we had only one version of ADF (published) and an editing (non-saved) version. In that case, every time you want to save your changes, required to click the “Publish All” button. This is not a very convenient way to work with ADF, for several reasons:
- Before writing, all objects in the ADF must be validated correctly
- Transitional changes (not fully finished) cannot be saved
- Your work can be lost or overwritten by another team member (the last publish counts)
- You simply can’t see a history of changes and ask for PR (Peer Review)
Having ADF associated with (GIT) repository – you’ll see extra options in the top menu, as shown below:

ADF editor with GIT connected (bottom) and without (top)
Once a connection to the GIT repository will be made – you can create your own branch (directly from ADF UI!) and all the above inconveniences disappear:
- Save your changes whenever you need without validation needs
- Avoid working on the same code with other developers
- Do follow the history of changes (each save do commit to the repo)
- Create Pull Request once your branch is ready to be merged to master (or collaboration) branch, which means: is ready to go!
- Switch between different version of the code (in a second) by toggling the branch! Boom!
At the time of writing this post, working in the deployed version of ADF and having GIT set up – “Publish” button is available, however, it is not a recommended method of making changes in that ADF instance. You’ll be warned by following message (until 31/07/2019 when that option will be off):
You have GIT enabled in your data factory. Publishing outside GIT mode, when you have GIT enabled, will be disabled July 31st 2019. Please reach out to us using the feedback button above if you have any concerns. Read about our Best Practices.
Continuous Integration and Continuous Deployment
Since now, we are working on ADF associated with GIT repo and interested in automation the process of deployment our changes made to ADF. Right. How to do that if not by Export of ARM Template? At the moment, is very important to understand how ADF cooperate with GIT and distinguish action hidden behind buttons: Save All and Publish.
Action: Save All
This button once clicked, commits all the changes and pushes them to GIT repository into the branch you’re working with (seen on the left of “Save All” button). Check this out by reviewing the history of commits:
Commit’s messages are generated automatically.
Action: Publish
The button can be used only from the (so-called) collaboration branch. Usually, the master branch plays this role.
During this operation, two actions are being performed:
- Publishes the current version of code to “deployed” version of ADF
- New branch “adf_publish” is created (if not exist) and changes are being pushed to the branch
Both operations can be found in the diagram below:
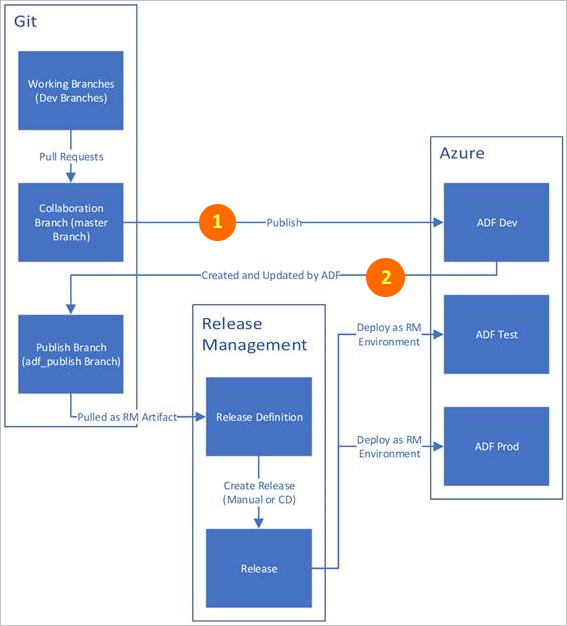
As you noticed – nothing extra is required to publish your changes to DEV environment (ADF Dev).
Afterwards, a special branch has been prepared and this one should be used to make other actions in order to promote ADF to other environments.
Bear in mind that the code in “adf_publish” branch has got a totally different structure comparing to what we have seen in our branch:
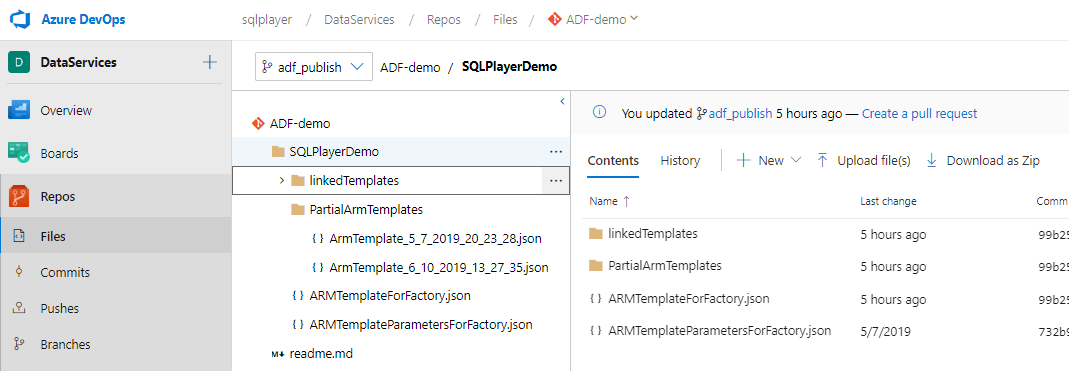
Structure of folders and files in adf_publish branch
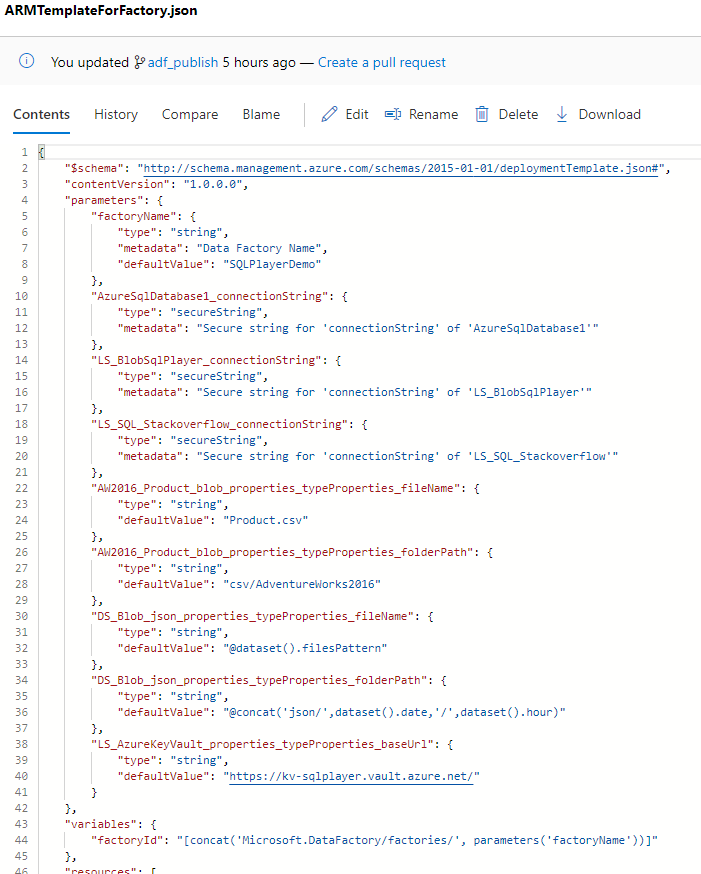
For the purpose of this post, we will be interested in only two files: ARMTemplateForFactory.json
and the second: ARMTemplateParametersForFactory.json
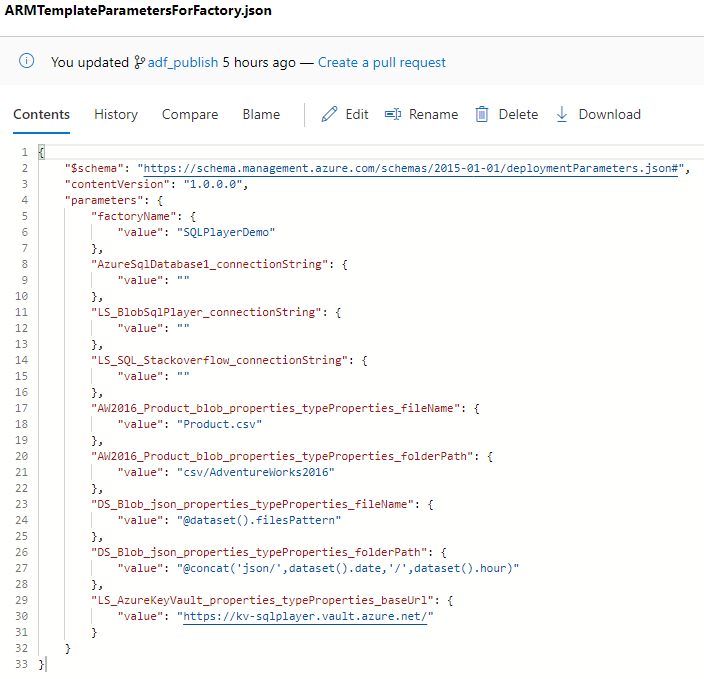
The first contains all objects of ADF, while the latter contains values for parameters. You’re at home when familiar with ARM Templates, right?
Build Pipeline
Now, we know how the structure of files in repo looks like and what we do need to deploy. Let’s focus on create build pipeline in Azure DevOps first. In Azure DevOps portal go to Pipelines and Builds, create a new build (New build pipeline).
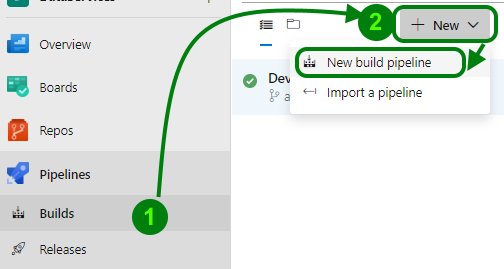
To create an empty build pipeline – choose “Use the classic editor to create a pipeline without YAML.” option. In the first step, we must select the source code repository for this build. For this demo purposes, I use internal Git repo (Azure Repos Git), my “ADF-demo” repository. As default value for branch, you will see the “master” branch and usually, it is good, but not in this specific (ADF) case.
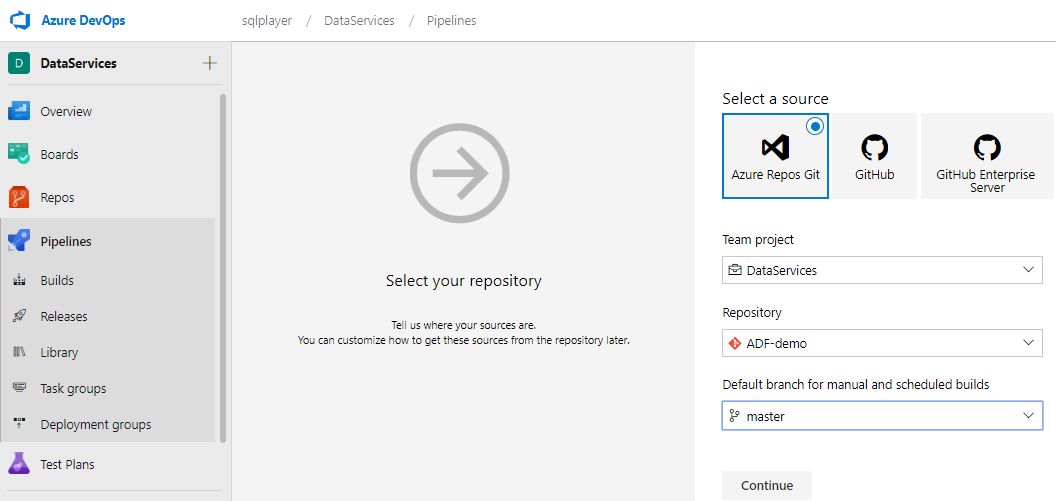
So, before click “Continue”, you must change source branch from (default) “master” to “adf_publish”. Then click “Continue”.
As we don’t want to use any template – click “Empty job” in order to go to further step.
Now, let’s configure some parameters for each section:
(Build) Pipeline
Do name your build pipeline and select agent who does the job. You can use one of the agents offered by the portal or yours one if you have got.
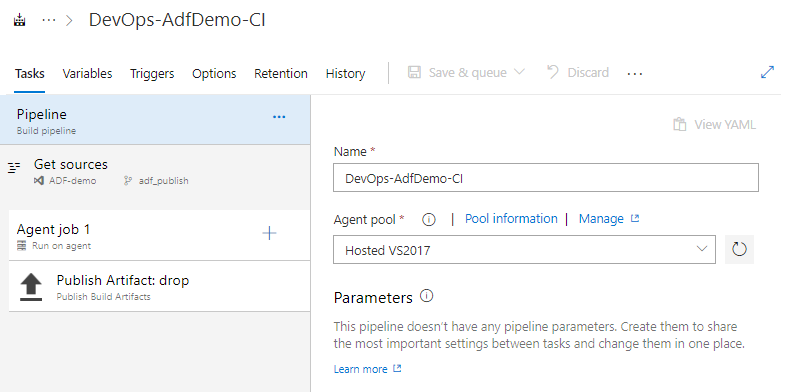
Azure DevOps: Build pipeline
Get sources
This section holds the pointer to the code repository to collect the code and it contains all the information you have provided in the previous step (Team project, Repository, Default branch). Again: it’s important: check if you have selected “adf_publish” as a source branch.
Agent job 1
This is the section when we might configure our requirements for the agent. As we are not very demanding here – you can leave all options by default.
Aim of a build process is to build a project and generate artifacts which will be used for deployment. As there is nothing to build here (ADF validates all object while publishing) – all we need to do here is simple copy files = publish artifact. Hence it’s time to add a new step for the agent. Click on “+” (plus) button onto “Agent job 1” and find “Publish Build Artifacts” task.
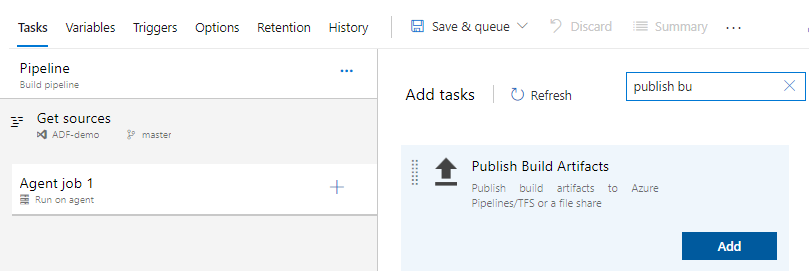
Azure DevOps: Adding a new task
Add a new task and configure it as shown below replacing “Path to publish” with your one:
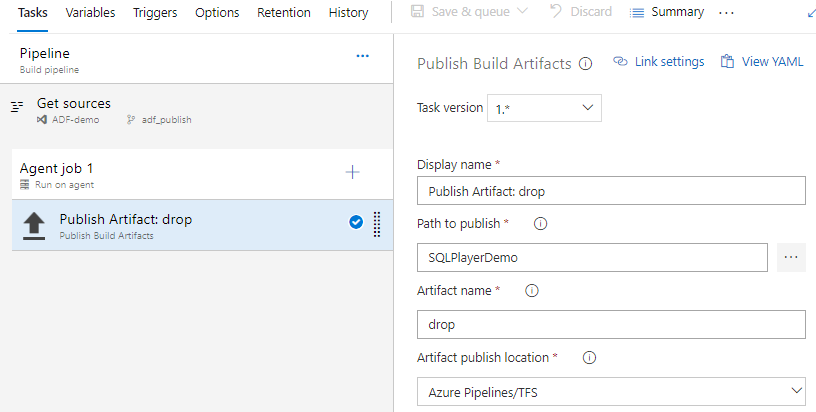
Azure DevOps: Configure Publish Artifact task
That’s all to build pipeline. Now you can Save & queue it in order to create your first ADF build.
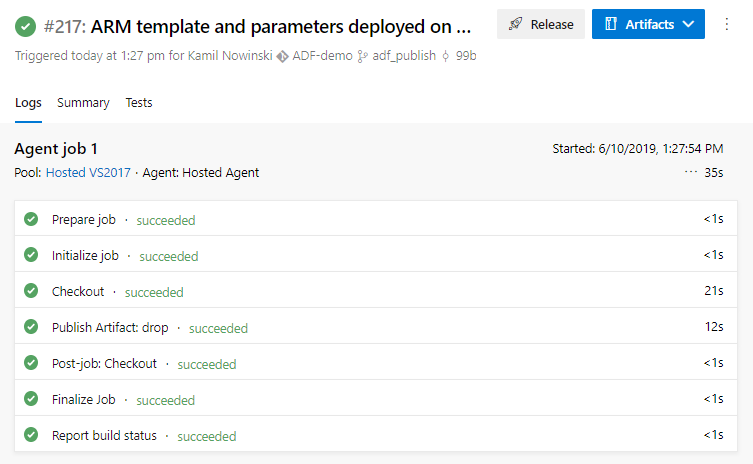
Release Pipeline
Once we have some artifacts prepared by build pipeline – we are ready to go with a deployment. Let’s create a new Release Pipeline, again without using any template (Empty job).
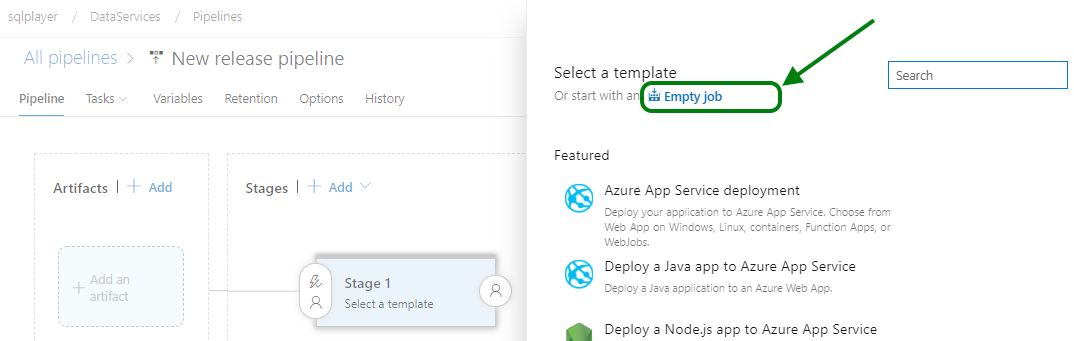
Azure DevOps: Creating a new release pipeline
Then, for Artifacts – click Add and configure Artifacts that have been created in Build Release phrase. Afterwards, do configure the first Stage (know as well as environments) calling it “UAT”. The next step is to add two tasks:
Tasks
ADF instance deployment
This is Inline script of Azure PowerShell type of task which creates ADF for us if that does not exist.
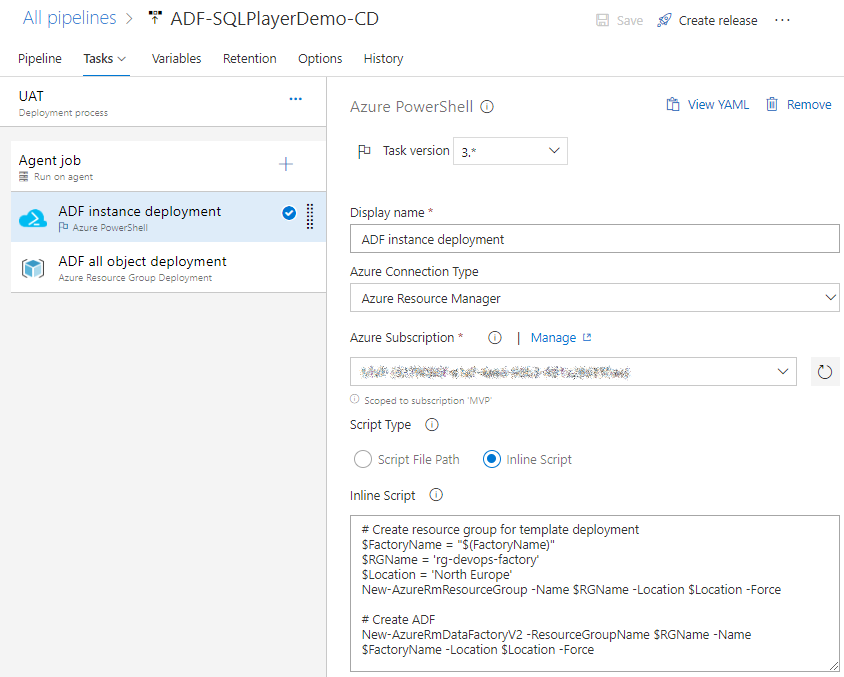
Azure DevOps: Instance of ADF deployment task
As you can see, I have used one parameter and hard-coded values for Resource Group name and Location. Both can (and should!) be replaced with variables.
ADF all object deployment
This step is for actual deployment of all ADF objects like:
- Pipelines
- Linked Services
- Datasets
- Data Flows
- Triggers
Just add new task type “Azure Resource Group Deployment” and configure all fields as shown below:
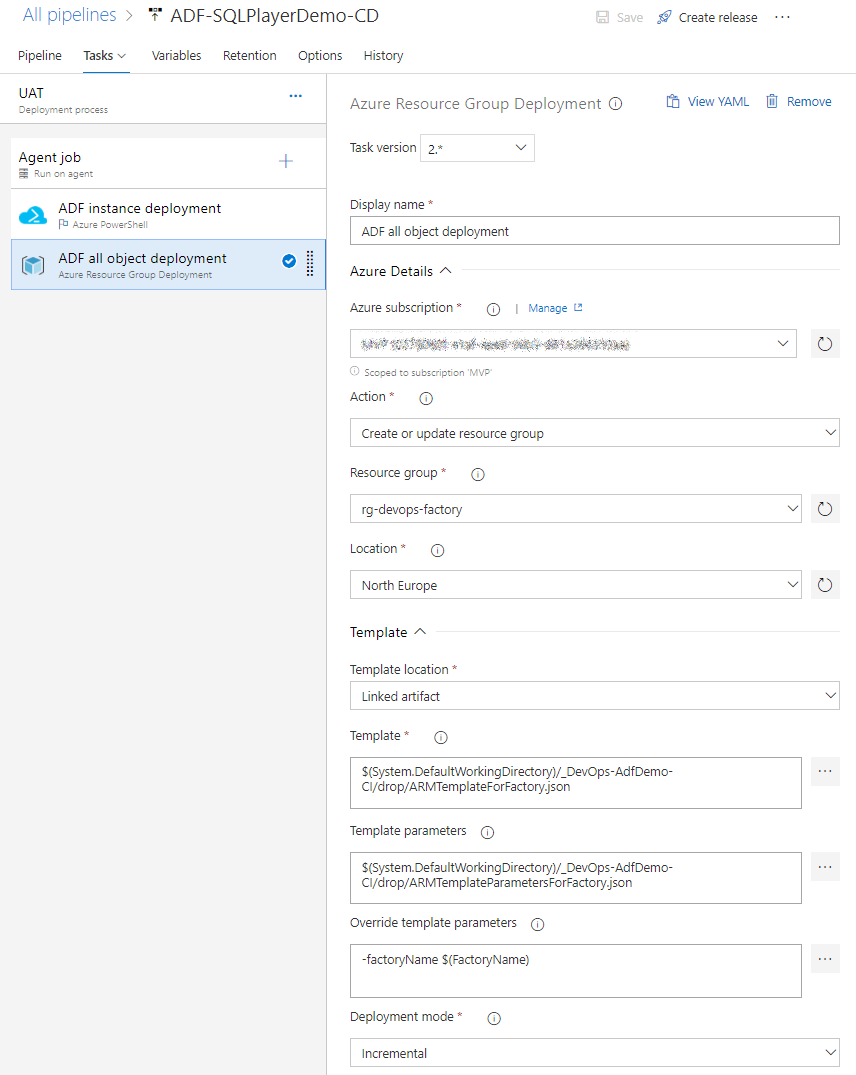
Azure DevOps: Deployment of all ADF resources (objects)
| Field | Value |
|---|---|
| Action | Create or update resource group |
| Resource group | Your name of RG created in the previous task in this pipeline |
| Location | Location of your ADF |
| Template location | Linked artifact |
| Template | $(System.DefaultWorkingDirectory)/_DevOps-AdfDemo-CI/drop/ARMTemplateForFactory.json |
| Template parameters | $(System.DefaultWorkingDirectory)/_DevOps-AdfDemo-CI/drop/ARMTemplateParametersForFactory.json |
| Override template parameters | -factoryName $(FactoryName) |
| Deployment mode | Incremental |
In your example, you must replace the build name, which is _DevOps-AdfDemo-CI in my demo. You also might have noticed that “drop” is an artifact name defined in Build Pipeline.
Another important parameter is “Override template parameters”. In that field, we can define all parameter values that should be replaced. It’s crucial to provide all required values that differ between environments otherwise values from template parameters would be used. Although it’s not the best method of replacing parameter values – in this post I wanted to simplify the process as much as possible.
Last but not least parameter is “Deployment mode”. You can select between “Validation Only”, “Complete” or “Incremental”. Even though we point out the complete version of ADF template (file) – Incremental mode must be selected here. Complete would remove the entire ADF instance, pretend that deploy everything else and finish without any error, but your ADF instance just… gone (has been deleted!). Check for yourself or watch this video where I documented out that behaviour (2’14” is the moment when ADF created a few seconds ago disappears):
So, remember then: “Incremental” mode is the only one correct option here.
PS. Yes, I know, the documentation said so, however it still strange behaviour to me.
Variables
If you’re not familiar with Azure DevOps very well – the Variables can be defined in Variable tab. Very briefly: they might be defined providing the values directly, defined for specific stage and also they can be provided by Azure Key Vault reading the values from its secrets. In this demo I’ve used only one variable, so you must define at least FactoryName.
Run, run release!
Once you finish creating a new Release Pipeline in the portal (don’t forget to save it) – it’s time to create new/first Release and deploy the code of ADF with fully-automated way. Do click on “Create release” and “Create” button in a new window.
Next step
As an extension to the above pipeline, you can clone the existing Stage (UAT) to prepare deployment for other environments, such as PreProd & Prod. If you do so, don’t forget to close variable(s) with correct values for these stages.
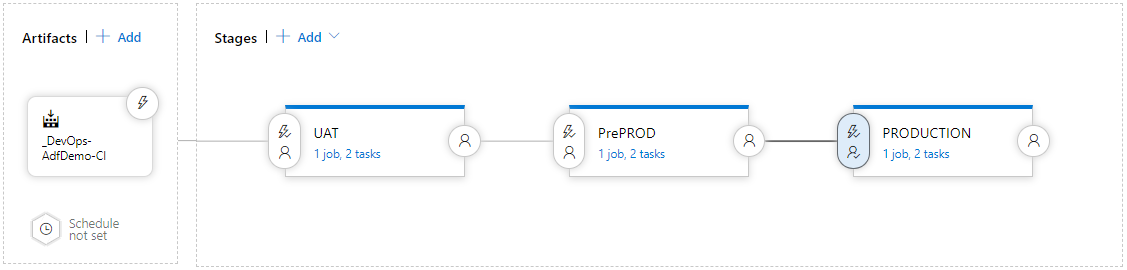
Adding Pre-Deployment approvals allow you control who/when will be able to deploy ADF with DevOps. This configuration, however, goes beyond the scope of this article.
Questions
Can I change the Git repository when my ADF is already hooked up to a different one?
Yes, you can. To achieve that you must disconnect ADF from current GIT repo and then hook up another one.
What code repositories are being supported by ADF now?
Currently, you can connect ADF to the following types of repositories:
- GitHub
- Azure DevOps Git
Conclusion
CI/CD process for ADF doesn’t similar to the others you might know. To be fair, it’s little intuitive when you look at it at the beginning. That’s why I tried to describe it as straightforward as possible, bearing in mind, that the post does not cover more complex scenarios. However, I believe that is a good start kit, but obviously, the best method of verifying is to give it a try yourself. In the next post of this series, we’ll take a closer look the way of passing parameters values in a more efficient and comfortable way.
Because many people asked me (including myself a few months ago) how to set up that process, many of us still have a mess in their head.
And because the process is relatively new – not too many have an idea of how to start with it. I hope this post has helped you at least a little bit to understand the process. Let me know if you have whatever questions about this and I will try to help.
More sources – links
Azure DevOps
Azure Friday: Continuous integration and deployment using Azure Data Factory
Visual authoring in Azure Data Factory
Continuous integration and delivery (CI/CD) in Azure Data Factory
Continuous integration and deployment using Data Factory
About author

You might also like

Deployment of Microsoft SQL database with Azure DevOps
Hello, data folks! I have published several articles about databases and their maintenance in SSDT project on the blog. One of the posts explained step by step how to import

Publish ADF from code to further environments
Struggling with #ADF deployment? adf_publish branch doesn’t suit your purposes? Don’t have skills with PowerShell? I have good news for you. There is a new tool in the market. It’s a task for Azure

{kind=link}
Mapping Data Flow in Azure Data Factory (v2)
Azure Data Factory is more of an orchestration tool than a data movement tool, yes. It’s like using SSIS, with control flows only. Once they add Mapping Data Flows to


40 Comments
abhi
June 26, 23:21hey thats a great documentation and I relate most of it playing around with it, however I have a scenario for you…
Consider we have dev test and prod environment of ADF v2. The dev environment is git integrated. The developers have debuged their changes and merged with collaboration branch after pull request. The changes are published and deployed to test environment first. Here many features are getting tested but few are ready for prod and few are not, how do we move the ones which are ready since the arm template takes the entire factory?
How do we hande this type of deployment scenario in Microsoft recommended CICD model of git/vsts integrated adf v2 through arm template
One thing can be that the debug is itself your test environment for developers, however since we cant apply trigger testing in debug mode hence we do need a test environment. Also we can test in dev enviroment data factory mode but then we should stop continuos build and release trigger as we need to first test and then deploy manually.
stackoverflow link:
https://stackoverflow.com/questions/56781684/deployment-scenario-of-git-integrated-azure-data-factory-via-arm-template
2nd question:
In some projects there will be repository level rules and branch policies like new branches with random naming conventions are not allowed or release should be only happen from master branch. In such cases how do we handle/recreate the functionalities of adf_publish branch which is created automatically.
One option is to change the publish branch forcefully to some other branch and then raising a pull request of Arm template files back to the master, however its not a good solution since there is 2 pull request involved and continuos build and release created are multiple and are wasted.
Your inputs would be highly appreciated.
Regards
Kamil Nowinski
July 01, 09:48Thanks Abhi for your comment!
First issue: For me, it’s all about GIT repository and the way how you manage your branches. ADF should be deployed as a whole. If you deployed some features which not ready for Production – a developer should revert it back in the code repository to make it ready for production. The scenario that you are describing sounds like experimental ADF. In that case, you might want to use either separate branch for developers and test it before the code comes to collaboration branch or separate ADF at all. It’s all up to you – find the best solution for your scenario.
abhi
July 01, 09:15any update?
Ritesh
August 15, 12:50Hi Kamil,
Now since 31st July deadline has passed and it looks like Microsoft has removed PUBLISH from Data Factory Mode.
Any option for Data Factory Mode to have Publish enabled?
If No, then what are the steps to migrate existing Pipeline/DataSets etc. to GIT enabled repository?
Thanks
Ritesh
Kamil Nowinski
August 22, 16:55Hello Ritesh,
I don’t think so. It was disabled intentionally with a warning in advance. However, there is an option to migrate existing code to GIT repo and have access to ADF code as a result. Simply – set up the repo as I described it in this post: https://azureplayer.net/2018/10/setting-up-code-repository-for-azure-data-factory-v2/
Thanks for reading and apologise for the late response (I’m on holiday right now). Let me know if the above post helps.
tree_branch
August 21, 23:55When you created your build, you mentioned the branch you are using is ‘Master’ as a source. But then in some screenshots you are using adf_publish. Isn’t the build sourced off the adf_publish branch?
Kamil Nowinski
August 22, 17:31Hi Ivan. Thank you for reading and vigilance. You are right! The second screenshot in “Build pipeline” shows “master” branch as a default value. In the next step, it should be changed to “adf_publish” because that branch is the right source of the build.
Good spot! I have just updated the post. Thanks!
Sidk
September 19, 06:03We have ADFv2 pipelines where we have parameters set to default values. These values need to be changed for test environment and then for production environment.
The parameters list does not show up these parameters, so can you guide on how to proceed with setting up parameters for adfv2 pipeline with values for test and prod
Kamil Nowinski
September 21, 10:20Hi Sidk.
It’s a bit tricky one, but you can override the default parameterization template, creating a file named arm-template-parameters-definition.json in the root folder of the repository. More details you can find here:
https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment#use-custom-parameters-with-the-resource-manager-template
I’m planning to write another post extending this blog post with such an advanced way of control what comes to a publish branch. Stay tuned.
oramoss
October 04, 21:58I’ve implemented the Release aspect of this at my current client but we only use the Release part – we don’t need to use the Build part. Is there any reason you involve the Build part in your process? I wonder if I’m missing something by not having it…
In our process we do changes in feature branch. Hit Push which says No, you can’t you need to raise a Pull request…fine…raise a PR, from feature branch to master…goes through fine. Leave that and go back to ADF, choose Master, now choose Publish and it accepts to do that…publishes and builds ARM template. Then we go back to ADO and use a Release to pick up adf_publish branch and push out to the Test or Prod environments as per your article. Build isn’t required in what we do…but I’m just wondering if I’m missing something…?
Kamil Nowinski
October 06, 23:40A build pipeline is not necessarily required. At the time when I was writing this blog post – the were two reasons. One is to keep the whole code as an artifact, for the record, as everything else we do. The second, you could modify parameters file to put/replace selected values with placeholders, but finally, I left it without such example, because it is not recommended way to achieve that goal. Next post (hope soon) explains how to control on what’s gonna be push to parameters file and how to put placeholders optionally.
oramoss
October 08, 21:23Thanks Kamil
If the code is via a git repository then we already have the codebase stored – not necessarily easily to point at a related release to be fair so perhaps as an artifact on a build that sounds quite reasonable actually.
Look forward to the next post.
Thanks
Jeff
HT
October 24, 15:20Thanks for an informative post Kamil. In this post, you created a build pipeline using the classic editor. Have you done one using the new YAML approach? The YAML option is not as intuitive for me and I am currently working through it. If you have done it, would greatly appreciate to see your YAML file or better yet, a revised post from you…cheers.
Kamil Nowinski
January 10, 21:36Happy to help. I haven’t prepared these pipelines as YAML yet. As soon as I do it – I will definitely share such a code.
AM
January 09, 13:13I have followed every step and was able to build CI successfully but when came to run CD i am facing issue in task “ADF instance deployment” which says
2020-01-09T13:09:21.6361030Z ##[error]A positional parameter cannot be found that accepts argument ‘-Central US’.
Kamil Nowinski
January 10, 08:38Hi AM. Did you check another region for test purposes? Can you send me a whole log of the task?
Azure Learner
January 10, 05:32I have scenario – having three data factories created for three different environments (Dev, Test, Prod). I have create pipeline to copy flat files from one azure storage container to other. To acheive this, i have created one linked service to Azure storage blob, two data sets (source and target references) and one pipeline with copy activity. I have integrated with Azure Repos Git.
I have started creating release pipeline to automate the deployment process in Test and prod environments. But I am not sure what are the parameters and where I need to change in the release pipeline for other environments. I see in above documentation, you have mentioned only one parameter (factory name), but in my case i think i need to mention (azure blob storage connection string, datasets etc for other environments).
It would be really great if you can create a post with above scenario end-to-end.
Kamil Nowinski
January 20, 21:51Hey Azure Learner.
I’m preparing a video to show such an end-to-end solution. Currently struggling with video post-production, but it should be published soon.
The recap of the passing year 2019 | SQL Player
January 14, 20:02[…] Deployment of Azure Data Factory with Azure DevOps […]
SAM
February 24, 07:49I have a question here. You said that ADF as a whole should be deploed everyitme. but if we make changes to only some of the things in ADF, then isn’t it a little overhead to deploy everything everytime even if it is not changed? If i have many test pipelines in my DEV environment, then i cannot deploy them to the QA or other stages right? Is there any way where i deploy only some things from the ADF and not everything?
Configure Linked Templates Use for Azure Data Factory with Azure DevOps Deployment – Oramoss
March 04, 08:25[…] this article from Kamil Nowinski I have a Build Pipeline “ADF-CI” in Azure DevOps which stores the […]
Vishnu
March 26, 08:58Hi Kamil,
Thanks for this.
Quick question. After all the changes have been merged into my dev collaboration branch and published. Is there a need to deploy it to DEV again? I have seen this CICD pipeline where it builds and deploy the data factory to DEV after the changes have been published.
PaulJohnBerry
April 09, 19:54Hi, Thanks for your article. When I delete a pipeline in DEV and then run the CI then the CD to my TEST DF the pipeline still exists in the TEST Arm Template, however other changes (modifications and additions to pipelines) successfully apply. Have you found this behavior yourself?
Kamil Nowinski
April 10, 14:13No, this shouldn’t happen. Make sure that you publish the changes once you delete the pipeline.
Alberto
June 16, 21:51Hi Kamil, you know that you are about to configure the DEVOPS for the ADF in the company and we are faced with the alternatives 1) 1 single ADF service and multiple branches and 2) multiple ADF services (DEV-PRD). Which do you think is better and why?
Kamil Nowinski
June 16, 23:00Hi Alberto. Only option 2: multiple ADF services (separate service per environment). Why? I don’t want to elaborate here too much (it’s worth blog post), but generally speaking, option 1 is impossible. Multiple (code) branches are for managing the development, not for switching code between environment. Furthermore, what would be the reason for having only one instance? The instance (of ADF) itself costs you nothing (or almost nothing).
Jagan
October 16, 10:05Hi Kamil,
Thanks for your document on build and deploy. While following your document, I am getting an error on task “ADF objects deployment” for the property “Override template parameters”.
Warning: Failed to download the template file from the given path ‘$(System.DefaultWorkingDirectory)/_Devops-ADF-CICD/drop/ARMTemplateForFactory.json’ with the following error: Downloading files larger than 2MB is not supported.
Though, I have increased the file size in Project settings on Azure devops, the error still occurs. Do you have any suggestions to overcome the error.
Thanks,
Jagan
Ferran
January 26, 08:45Hello!
Thanks Kamil for your explanation and also for your videos. It’s not easy to find well explained information on this topics and your videos are very clear.
I have the same issue than Jagan. How are you doing Jagan to change the file size in project Settings?
Kamil, how should we do to overcome the error?
Thanks!
Regards,
Ferran
Orhan Celik
March 30, 07:16Jagan, For the error on “Downloading files larger than 2MB is not supported”, the solution is to use “Linked Resource Manager templates” as explained in ADF documentation https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment#linked-resource-manager-templates
Enrico
November 04, 12:41Hello Kamil,
first of all great explanation and thanks for the time spent in this article!
I have a question about the whole procedure. This is not fully CI/CD compliant and in my company we are trying to make it as such. What is missing? That “Publish” button on the ADF portal is something I want to do programmatically and yet I haven’t found a solution. Since the whole code is in a git repo, sometimes I make changes on the code itself and don’t go into the ADF portal for example. When I merge the changes into Master I want also that “Publish” button to be hit automatically and the changes being merged to “Adf_Publish”. How to do this on Azure Devops? Maybe through some powershell script? Thanks in advance!
Kamil Nowinski
March 30, 10:33Enrico.
I understand your pain. You are right, there was no way to automate this. Until 2021. Microsoft released npm library which allows exporting arm_template of a given ADF. “Build ADF” task of my extension simplify entire work, so instead of doing it manually via ADF UI, you can do that via Azure DevOps Build Pipeline (CI). Take a look here: https://marketplace.visualstudio.com/items?itemName=SQLPlayer.DataFactoryTools#buildtest-azure-data-factory-code . I will prepare a post about this soon.
Chris
October 05, 10:28Hello Kamil,
I am also having the same issues of the “Publish” button needing to be manually pressed. The link above shows an Azure Devops task, however we don’t use Azure Devops (we use GitHub and Harness).
Do you know if there is a powershell command / similar that can perform this task so we can run it as a github action?
Thanks in advance.
CI/CD for Azure Data Factory: Create a YAML deployment pipeline - Craig Porteous
November 25, 13:31[…] https://azureplayer.net/2019/06/deployment-of-azure-data-factory-with-azure-devops/ […]
Swapna
November 28, 11:01Hi , Nice Article.
I have build release pipeline exactly as described her. Its working fine we are working on one project at a time. I can see that adf_publish branch code is moved to QA, UAT and Prod DF. But our scenario is that we work in multiple developers work in multiple projects by creating feature branch from master branch in DEV ADF instance.
In this case we end up having code in master which cant be released to prod as it has code from other feature branches which are yet to be tested in QA and UAT. How to handle this scenario.
Kamil Nowinski
November 28, 18:03Hey Swapna. Thank you.
I understand your case. It’s very often seen situation in mature organisations who use the tool with the conjunction of a higher level of branching strategy in git. I can’t advise you using Microsoft’s approach as I’m not its advocate and I gave up with ‘adp_publish’ branch a long time ago. I deploy ADF directly from the code (JSON files) for many reasons – one of them is the limitation on branching strategy. Take a look at this page: https://azureplayer.net/adftools/
Two methods of deployment Azure Data Factory | SQL Player
January 15, 20:26[…] to dig deeper about how to deploy ADF with this approach as I already described it in the post: Deployment of Azure Data Factory with Azure DevOps. Why many people (including me) do not like this […]
Configure Linked Templates Use for Azure Data Factory with Azure DevOps Deployment -
January 25, 17:34[…] this article from Kamil Nowinski I have a Build Pipeline “ADF-CI” in Azure DevOps which stores the […]
Reva
June 06, 12:54Hey Kamil,
This explanation was really helpful for my own work. Thanks for that. Scrolling through comments and even in the blog post you mentioned about doing a video/post on using parameters efficiently in the pipelines. Is this available now ? Could you add a link to it ?
QA Er.
August 01, 18:40Would definitely be very helpful. Waiting on it too.
Henry
July 06, 06:42Hi kamil,
I just saw you update a new task: ADF Deployment from ARM Template files. I’m appreciate what you have done it’s really help me a lot. And about the new tools I got some question for you. Did it will faster than before when we do the deploy? And did it solve the limitations about ARMTemplate 4MB size? Really hope you can reply me one day.