

Synapse Analytics workspace – deployment challenges
Azure Synapse Analytics is not just “another service” in the Azure. It’s very comprehensive set of tools rather than one-goal-tool (like Azure Key Vault or even Storage Account).
On the documentation page we can read:
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated options—at scale. Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, transform, manage, and serve data for immediate BI and machine learning needs.
As you can see, Microsoft uses word “worlds”. Those areas are as much big as worlds (thankfully not “universe”! … yet). Simultaneously, Microsoft does all their best to make it user-friendly and easy for end-users or developers to achieve what they need.
And all these things are good, until… you will try to automate the deployment of the entire workspace (our universe – where all worlds belong to).
Twitter Poll
Like almost 3 years ago with ADF, I felt like there is still tons confusion of how to deploy Azure Synapse automatically and it’s about time to ask similar question to #AzureFamily. So I did and there is the result:
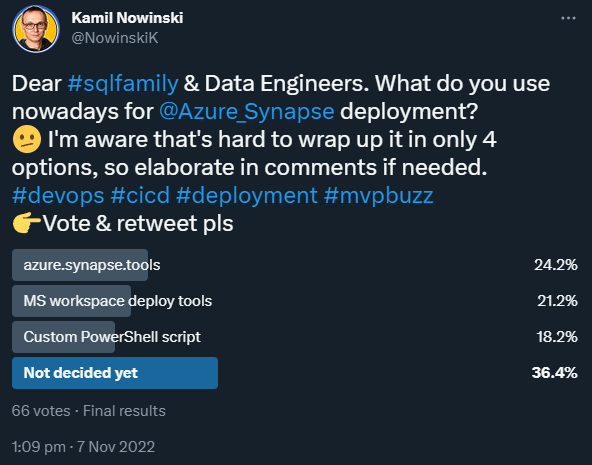
As you can see – I was right with my suspicious. People out there are either not decided yet what approach or tool to use nor they use vary approaches.
And that is because the whole complexity of Azure Synapse and its deployment. Then you may ask:
Kamil, but why the deployment could be so much complex?
Why complex?
If you follow me for a while, you might have seen my blog post about Two methods of deployment Azure Data Factory. That my journey started over 2 years ago and indeed some parts were difficult. Since then I prefer to deploy ADF from code (second approach) only.
For Synapse Analytics, there are even more various components belong to the ecosystem. Hence, it’s important to do it right. Right? Appropriately for the entire Data Platform and beyond. So, keep an eye on best practices and remember about limitations.
We are talking about a deployment here. Not manual deployment, but automated process. Ideally, we would like to build pretty decent and fast enough CI/CD process (potentially with Azure DevOps). Therefore, we should seriously consider a separation of two areas of Synapse Analytics workspace: Infrastructure – this will be deploy first, Application – this will be deploy as a second one assuming all infrastructure parts underneath are already deployed. The code of these two should be separated across separate folders in the same repository, or going further, you can split them even across separate repository (very likely under the same project).
What do I mean here?
From high-level perspective, I won’t be able to see…

… and recognise some details as shown below:
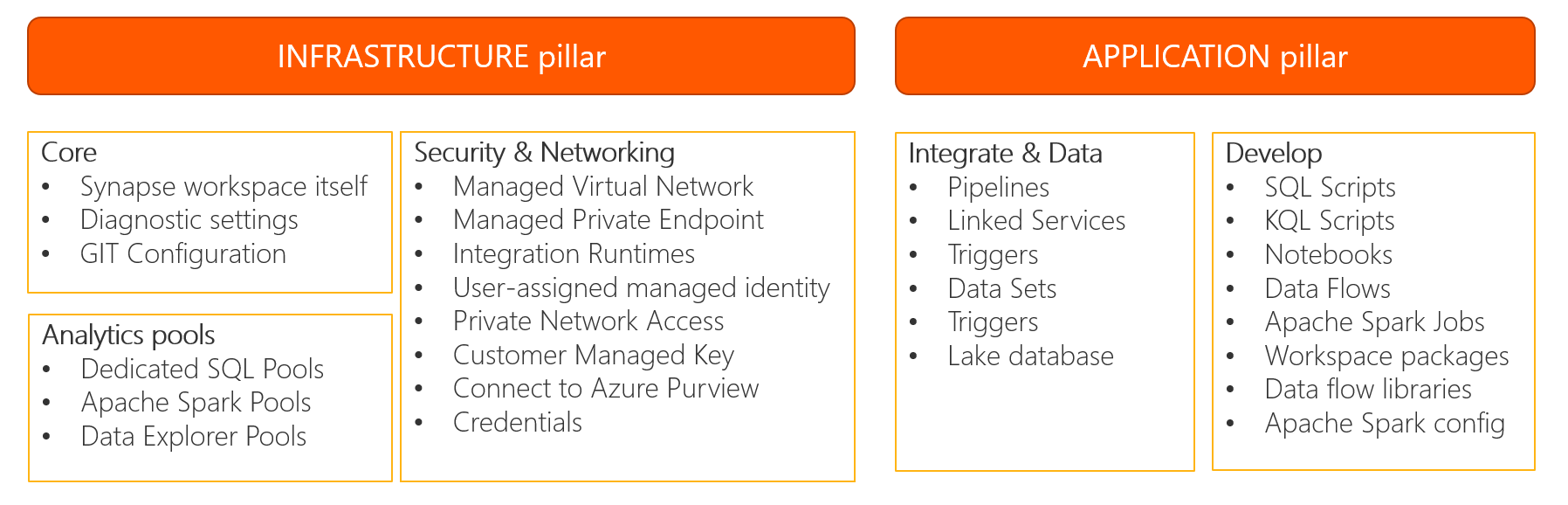
There are two pillars: INFRA & APP.
Why does it worth to distinguish these two?
- Various frequency of deployment (SDLC) between Infra vs App
- Separate team’s responsibility of Infrastructure part
- Security and costs control over Infra
- Faster development and more changes to the App repo/folder
If you know any other good reasons for that – let me know in the comments section below.
World #1: Infrastructure
The following Synapse objects should be deploy as part of Infrastructure:
- Workspace instance
- Integration runtimes
- Managed VNET + Endpoints
- GIT Integration
- Pools management:
- Dedicated SQL Pool
- Serverless SQL Pool (other than default)
- Spark Pool
- Credentials
- Synapse Access Control
Deployment Solution
1) BICEP or ARM Template (Azure)
BICEP is a domain-specific language (DSL) for deploying Azure resources. It provides a simpler, more intuitive syntax for describing Azure resources and their dependencies than the traditional Azure Resource Manager (ARM) templates. With BICEP, you can write declarative infrastructure as code (IaC) that is more concise, readable, and maintainable. BICEP files are compiled into ARM templates, which can be deployed using standard Azure deployment methods such as the Azure CLI, Azure PowerShell, and Azure DevOps.
BICEP offers several advantages over ARM templates, including built-in functions, parameter validation, and better tooling support. BICEP makes it easier and faster to deploy and manage Azure resources, while reducing the risk of errors and simplifying the process of updating and maintaining your infrastructure.
Then, when it comes to deploy Infrastructure part of Synapse Analytics – I recommend to use BICEP.
Not sure how to build BICEP file and deploy Synapse with all satellite services? This GitHib repository is a deployment accelerator based on the reference architecture described in the Azure Architecture Center article Analytics end-to-end with Azure Synapse. This deployment accelerator aims to automate not only the deployment of the services covered by the reference architecture, but also to fully automate the configuration and permissions required for the services to work together.
2) Terraform (Cloud agnostic)
or… if your cloud environment or client standard requires you to use Terraform.
World #2: Orchestration (app)
The first and the most important part of Synapse Analytics workspace, right after Infrastructure, is all orchestration objects:
- Triggers
- Pipelines
- Datasets
- Mapping Data Flow
- Linked Services
- SQL Scripts
- Notebooks
Deployment Solution
1) azure.synapse.tools (PowerShell module)
Disclaimer: I’m the author of the project. It’s been cloned from very successful ADF edition.
I must admit this time Microsoft Synapse’s team got lesson learnt and brought the CI/CD tool for Synapse to the higher level.
In the same time, PowerShell for Synapse (Az.Synapse | PsGallery) have many gaps & inconsistency to be used for a deployment from code as I’ve done for ADF.
Hence, still in preview, so should be used in Dev or PoC environments only rather than in Production.
Furthermore, due to complexity of Azure Synapse product and maturity of Microsoft’s DevOps extension (see below), I do not expect very intense development of this project in a long-term horizon. Keep reading.
Link to GitHub repo: azure.synapse.tools
2) Microsoft Synapse workspace deployment (DevOps extension)
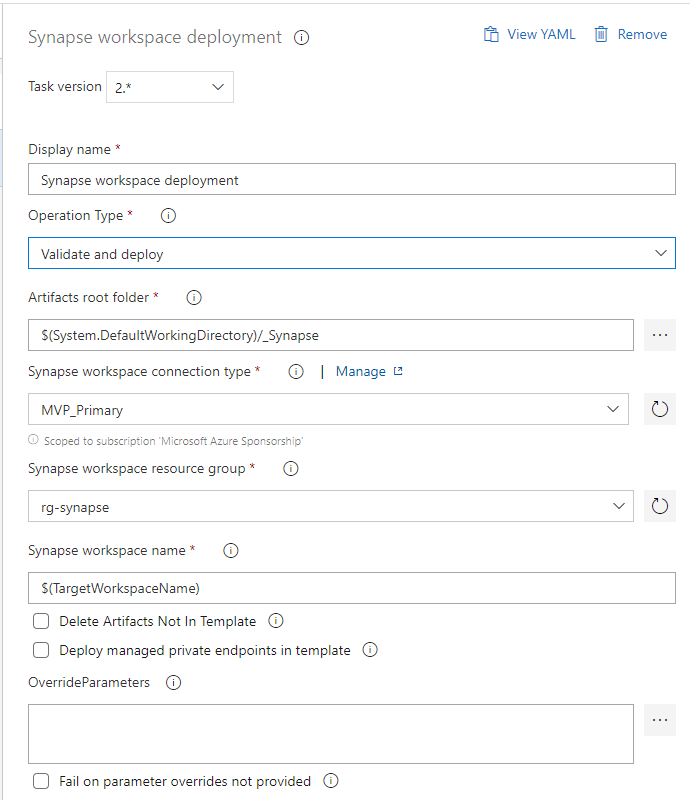
This time Microsoft did good job when it comes to the deployment of this Azure component. Similar task was not offered by Microsoft for Azure Data Factory. The extension to Azure DevOps contains only one task which offers 3 operation types:
- Validate – it validates the whole code from repo and generates ARM Template files. It’s only available in YAML version of pipeline.
- Deploy – publishes provided ARM Template to target Synapse workspace
- Validate and Deploy – in one-go action you’ll do both actions mentioned above (not recommended)
What is not supported:
- Resources, like pools management and workspace itself – see Infrastructure section above to deploy these things;
- Incremental deployment
World #3: Serverless SQL Pool
I’m not talking here about pool itself, where one will be deployed by default. If you need more serverless SQL pools you can always create them and then deploy – but that’s Infrastructure pillar (see above).
In here, I’m talking about all objects related to it, calls “metadata”:
- Lake database
- External tables
- External views
- External file formats, etc
There is no SSDT support for Serverless SQL Pool (yet), therefore we must build our own bespoke solution to create such objects by executing scripts incrementally. It can be done manually (not preferred option), or as a post-deployment step via PowerShell script or PySpark code.
Potential Solutions
Ha. None. Or almost none. There are some options but none of them are ideal and simple. Let’s deep dive:
1) Redgate Flyway – does not work with Synapse
My first, natural choice, was Flyway, the tool for migrating databases from one version to the another by executing incremental scripts. Unfortunately, when I tried to use it against Azure Synapse serverless SQL endpoints, it says: `Unknown SQL Server engine edition: 11`. I updated the ticket already created by other user in Flyway GitHub, but apparently there is no business justification for Redgate to introduce such update.
2) DbOps (PowerShell)
DBOps is a Powershell module that provides Continuous Integration/Continuous Deployment capabilities for SQL database deployments. The deployment functionality of the module is provided by DbUp .Net library, which has proven its flexibility and reliability during deployments.
You must remember to point out “nothing” for table monitoring versions:
Install-DBOScript (with -SchemaVersionTable $null)
Therefore, all scripts deployed in such scenario should be idempotent and re-runnable. Not that much funny scenario…
3) SQL Server Data Tools (SSDT)
If you are not familiar with SSDT – I have a few videos on my YouTube channel as well as comprehensive course on Learn with Azure Player platform.
Wait… you said it’s not supported (yet). Yes, because this is what Microsoft says:

However… The very latest updates say that there are some options (features) available in SSDT to work with Synapse SQL Serverless. My MVP fellow, Kevin Chant, wrote about this last weeks some posts:
- Deploying a dacpac to a serverless SQL pool (15/02/2023) – in here Kevin explains how to extract (from physical instance of SQL) & deploy DACPAC to other instance using SQLPackage.
- Homemade serverless SQL Pool Database Project (28/02/2023) – this time there is a nice try of creating database project using dotnet, and afterwards: build it and deploy using SqlAzureDacpacDeployment task from Microsoft.
Well, IMO it’s fair saying SSDT still doesn’t support Synapse SQL Serverless, at least for two reasons:
- The edition is not available in Visual Studio
- External file format generates issues which suggest it’s not yet supported
While we could live (for some time) with lack #1, the problem #2 is serious as in most cases we need SQL Serverless in Synapse to create External tables, which is not possible without External file format.
Bear in mind there will be new updates in this area, so I will be updating this post as soon as I spot something new.
4) Custom solution with Python and Pandas for an incremental deployment
Last year (2022) during DataRelay, in Birmingham I saw Arthur Steijn‘s session who visited us for the first time from Rotterdam, The Netherlands. He presented his custom solution on project he was working on, and afterwards I asked him to share the code with me and he did even more creating blog post.
World #4: Dedicated SQL Pool
Dedicated SQL Pool is something previously known as “Azure SQL Data Warehouse”. Please do not confuse it with Data Warehouse you built in on-premise environments. This one is MPP architecture. Check out my session from SQLBits 2020 conference and/or the slide deck: “When and how to… migrate to Azure Synapse?”. Having said that, we might have the following type of objects to be deployed:
- Tables
- Views
- Stored Procedures & functions
- Security
Deployment Solution
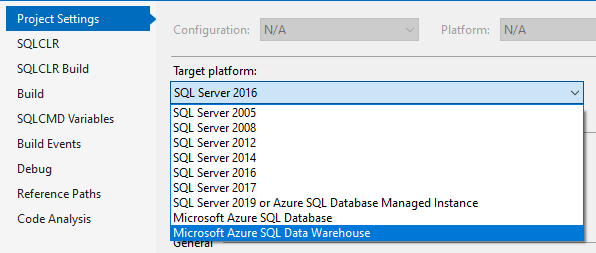
Hopefully, there is SSDT edition for Dedicated SQL Pool in Azure Synapse.
SSDT is SQL Server Data Tools, extension for Visual Studio that allows you to manage database project and deploy it incrementally by comparing project to the target server code. It’s very useful (state-based) approach available for Microsoft SQL databases (see supported target platforms on the picture aside).
World #5: Power BI
No additional efforts are required. All you need to do is Linking a Power BI workspace to a Synapse workspace, which actually is other way round, but’s ok. In this case, you’ll create new Linked Service and that’s all. Once your workspaces are linked, you can browse your Power BI datasets, edit/create new Power BI Reports from Synapse Studio.
Wrap up
This is the first version of this article. I will update this post from time to time as many things is being changed around few areas described above here.
Open for discussion, question and suggestions.
About author

You might also like

ADF – Deployment from master branch code (JSON files)
In the previous episode, I showed how to deploy Azure Data Factory in a way recommended by Microsoft, which is deployment from adf_publish branch from ARM template. However, there is

SSDT (SqlPackage) thread crashes with error when publishing
In this post, I will show you one of the scenarios when SSDT (SQL Server Data Tools) can fail unexpectedly while publishing database project to target server or preparation of

{kind=link}
Tokenization of database project in SSDT
SSDT project has something we call Variables. On the Internet (posts, forums) they also are known as placeholders or tokens, especially when talking in a deployment/CI/CD/DevOps context. Variables can be found for


0 Comments
No Comments Yet!
You can be first to comment this post!