

ADF – Deployment from master branch code (JSON files)
In the previous episode, I showed how to deploy Azure Data Factory in a way recommended by Microsoft, which is deployment from adf_publish branch from ARM template.
However, there is another way to build CD process for ADF, directly from JSON files which represent all Data Factory objects.
In this video, I will show you the latter method, building the entire process step-by-step, including the fact that we have multiple environments and wherefore isolated services. Therefore, we need to manage all the needed properties, correctly.
![]()
IMPORTANT NOTICE:
Update @ 02/06/2020:
Since now, I recommend this extension to Azure DevOps only, if you plan to deploy ADF from code.
Extension: Deploy Azure Data Factory by SQLPlayer
It is free from objects dependencies issue and does all the work in one task. Check it out.
Update @ 02/05/2020:
Alternatively, you can use Azure PowerShell task in Azure DevOps and use a brand new PowerShell open-source module to publish the whole Azure Data Factory code from your [master] branch or directly from your local machine. The module resolves all pains existed so far in any other solution, including deployment part of objects, deleting objects not existing in the source any longer, stop/start triggers, etc.
More details and full documentation with code is in GitHub:
https://github.com/SQLPlayer/azure.datafactory.tools
People are still divided on how to deploy ADF:
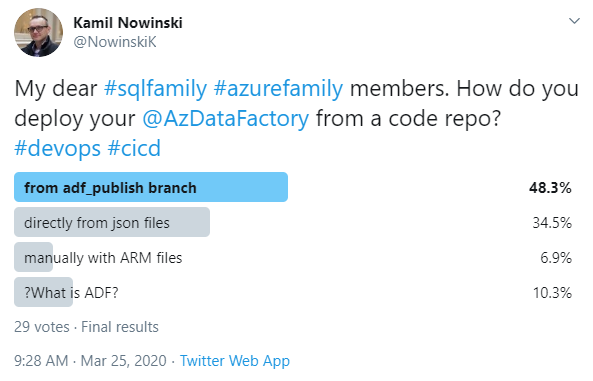
Links
The series about ADF on SQLPlayer blog.
Extension to Azure DevOps I used in this episode.
About author

You might also like

Last week reading (2018-09-30)
Entire last week was dimmed by MsIgnite, hence take a look at videos from that conference: Microsoft Ignite 2018 Some sessions recorded and available over there. CosmosDB at Ignite 2018

Set up connection from Azure Data Factory to Databricks
Both, Azure Data Factory and Azure Databricks offer transformations at scale when it comes to ELT processing. On top of that, ADF allows you to orchestrate the whole solution in

){kind=link}
ASF 015 video invitation
“This was in Dallas, we had our MVP Summit in Dallas and there were only maybe like less than 10 SQL Server MVPs.” Do you want to know who has


14 Comments
ram
April 23, 20:22Great content and thank you for sharing this.
Is it possible to just publish only the changed json files with this approach rather than publishing all the json files all the time?
Kamil Nowinski
April 23, 23:07Thanks Ram for your kind words.
No, at the moment it’s not possible to deploy the changes incrementally. But, I’m working on something new, where one of the features will give you that capability.
Please check this Power Shell module out:
https://github.com/SQLPlayer/azure.datafactory.tools
Yash
June 23, 06:57Great video Kamil.
Can you please let me know on how we can check on hot-fix part. i.e. We came across an issue in production branch and want to apply the hotfix first in production and then UAT /Dev stage.
Kamil Nowinski
June 23, 10:27Hello Yash and thanks.
For hot-fixes, you should create a separate branch (e.g. “hot-fix”) based on production (“master”), fix the issue in there and deploy the code into required environments (PreProd). Then those changes should be merged into “master” branch and publish to the Production environment. More details in future videos.
Yash
June 26, 22:54Thanks Kamil… Also, we have multiple developers in our team who need to use same ADF for development purposes. This code will be merged back to master and then go to UAT and so on.
Each developer is being allocated with his own SQL Server and Storage, If everyone starts creating the separate linked services for development, this number will grow exponentially which might give issues on deploying code to other environments etc.
Do you have any recommendation on how we can deal with this situation.
Kamil Nowinski
June 27, 09:17Sure. It’s a very good practice to have isolated databases for developers. In that case, each developer should work on its separate branch (ADF) and merge all changes (features, including pipelines, datasets, etc), except e.g. Linked Service(s) whom pointing to its own resources.
Yash
June 27, 19:19Great .. I was under assumption that by default all components gets merged (including Linked service) and we do not have any control over it. Do I need to use any customized components for excluding linked services from merge.
Yash
June 30, 19:20Hi Kamil, It looks like the developers created datasets will refer their development phase linked service.
Datasets might give issues on other environments if we wont merge the linked services.
Do you have any inputs on how we can handle that situation 🙂
Kamil Nowinski
July 24, 16:04Hi Yash. Apologize for a late reply. Do check out this post of Adam Paternostro from Microsoft who has described how to manage code, including branches for new features and hotfixes:
https://github.com/AdamPaternostro/Azure-Data-Factory-CI-CD-Source-Control
successhawk
September 04, 14:27Hi. Great content. Can you provide a pros and cons list for each approach (Microsoft’s proposed ARM vs. this)? Why would someone choose one over the other? It does appear to me that this is better but I would like to see your experienced opinion.
Kamil Nowinski
September 04, 19:16I will prepare the whole blog post about it. Hopefully, this month yet.
bharani
October 23, 16:15Hi, I have downloaded and configured your devops plugin. Thanks for your initiative. I am stuck in a place where I have to override service principal key value of a data lake / storage. From Git samples I only see that you are excluding “linkedService,BlobSampleData,-typeProperties.encryptedCredential” encrypted credential. I tried taking the encrypted creds from dev and tried to use the same for test adf but did not work. Is there a way to make this work without manually changing linked service values in test adf.
Ravitej
March 30, 14:30I can see the tool has some issues .
It throw the below error if i use the module
2023-03-30T14:27:52.1850099Z ##[error]Cannot process argument because the value of argument “name” is not valid. Change the value of the “name” argument and run the operation again.
Where should I set this name.
Note: Environment (stage), i kept this as blank as i dont have anything to declare in this csv file.
Kamil Nowinski
March 30, 16:08If you are talking about #adftools – this is the place where you can raise issues:
https://github.com/Azure-Player/azure.datafactory.tools/issues