

Mounting ADLS point using Spark in Azure Synapse
Last weekend, I played a bit with Azure Synapse from a way of mounting Azure Data Lake Storage (ADLS) Gen2 in Synapse notebook within API in the Microsoft Spark Utilities (MSSparkUtils) package. I wanted to just do a simple test, hence I followed the documentation from Microsoft: How to use file mount/unmount API in Synapse.
Having an ADLS Account already created in a subscription – should be easy peasy, right?
Currently, there are three authentication methods supported:
- Linked Service,
- Account Key,
- SAS token.
I used recommended method, which has access via Linked Service.
Problem
The first problem I faced when tried to run the first cell in a notebook (modified from doc):
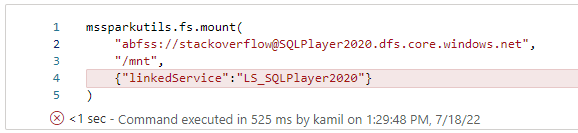
with the following Trackback below:
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<ipython-input-9-a8dbf6952053> in <module>
2 "abfss://stackoverflow@SQLPlayer2020.dfs.core.windows.net",
3 "/mnt",
----> 4 {"linkedService":"LS_SQLPlayer2020"}
5 )
~/cluster-env/env/lib/python3.6/site-packages/notebookutils/mssparkutils/fs.py in mount(source, mountPoint, extraConfigs)
37
38 def mount(source, mountPoint, extraConfigs={}):
---> 39 return fs.mount(source, mountPoint, extraConfigs)
40
41 def unmount(mountPoint, isLH=False):
~/cluster-env/env/lib/python3.6/site-packages/notebookutils/mssparkutils/handlers/fsHandler.py in mount(self, source, mountPoint, extraConfigs)
115 def mount(self, source, mountPoint, extraConfigs={}):
116 self.check_types([(source, string_types), (mountPoint, string_types), (extraConfigs, dict)])
--> 117 return self.fsutils.mount(source, mountPoint, extraConfigs)
118
119 def unmount(self, mountPoint, isLH=False):
/opt/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in deco(*a, **kw)
67 def deco(*a, **kw):
68 try:
---> 69 return f(*a, **kw)
70 except py4j.protocol.Py4JJavaError as e:
71 s = e.java_exception.toString()
/opt/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling z:mssparkutils.fs.mount.
: com.microsoft.spark.notebook.msutils.VerifyAzureFileSystemFailedException: [pre-verify before mount] request to https://SQLPlayer2020.dfs.core.windows.net/stackoverflow?directory=/&maxResults=1&recursive=false&resource=filesystem failed with exception - {"error":{"code":"OutOfRangeInput","message":"One of the request inputs is out of range.\nRequestId:8670ebf7-601f-00d6-5da2-9a7d0c000000\nTime:2022-07-18T12:29:48.6231547Z"}}.
at com.microsoft.spark.notebook.msutils.impl.mount.MSFsCommonMountUtils.verifyAzureFileSystem(MSFsCommonMountUtils.scala:153)
at com.microsoft.spark.notebook.msutils.impl.mount.MSFsMountUtilsImpl.mount(MSFsMountUtilsImpl.scala:70)
at com.microsoft.spark.notebook.msutils.impl.MSFsUtilsImpl._mount(MSFsUtilsImpl.scala:149)
at com.microsoft.spark.notebook.msutils.impl.MSFsUtilsImpl.mount(MSFsUtilsImpl.scala:522)
at mssparkutils.fs$.mount(fs.scala:37)
at mssparkutils.fs.mount(fs.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.microsoft.spark.notebook.msutils.VerifyAzureFileSystemFailedException: {"error":{"code":"OutOfRangeInput","message":"One of the request inputs is out of range.\nRequestId:8670ebf7-601f-00d6-5da2-9a7d0c000000\nTime:2022-07-18T12:29:48.6231547Z"}}
at com.microsoft.spark.notebook.msutils.impl.mount.MSFsCommonMountUtils.verifyAzureFileSystem(MSFsCommonMountUtils.scala:146)
... 16 more
And because the 4th line was highlighted, I thought “ok, probably my Linked Service is wrong. Let’s check it out”. Then I opened my “Manage” hub, select “Linked Services” item in menu and clicked my LS_SQLPlayer2020 to edit it:
![]()
Then, I click the “Test connection” button (right-bottom) and it says:
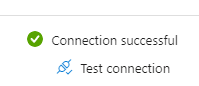
Great, Linked Service is configured correctly and works fine.
Investigation
Let’s double-check the log then, which is not very helpful, but I focused on this part:

“OutOfRangeInput” might suggest that a function tries to read some item which doesn’t exist in an array. That’s at least what my VB/C#/Python developer side of me whispered to me. In the first input parameter: “abfss://stackoverflow@SQLPlayer2020.dfs.core.windows.net” – the first word means container. Therefore, I double-checked if I really have “stackoverflow” container in the storage. I had.
Then, after doing some research on the Internet and trying a few other things – I realised what was wrong.
Solution
That error message sometimes means you got either your account name or account key wrong. So if you attached with name and key or a connection string, please confirm you typed your account name right and that the key you are using is up to date.
The above answer comes from Matthew Rayermann (MSFT) who replied to a similar issue here on GitHub.
Therefore, I revisited my code and change it to the following:
mssparkutils.fs.mount(
"abfss://stackoverflow@sqlplayer2020.dfs.core.windows.net",
"/mnt",
{ "linkedService":"LS_SQLPlayer2020" }
)
Can you see the difference? In the second line – the name of the ADLS account must be lower-case (see: Resource name rules – Microsoft.Storage). I made this mistake by simply copy/paste part of the name from the Linked Service. When I resolved the issue, the command executed in 10 seconds, and then I was able to test a few other steps:
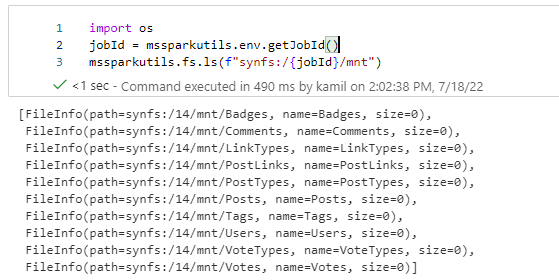
The goal of this test was to verify if my container is correctly mounted and has the right to read all folders.
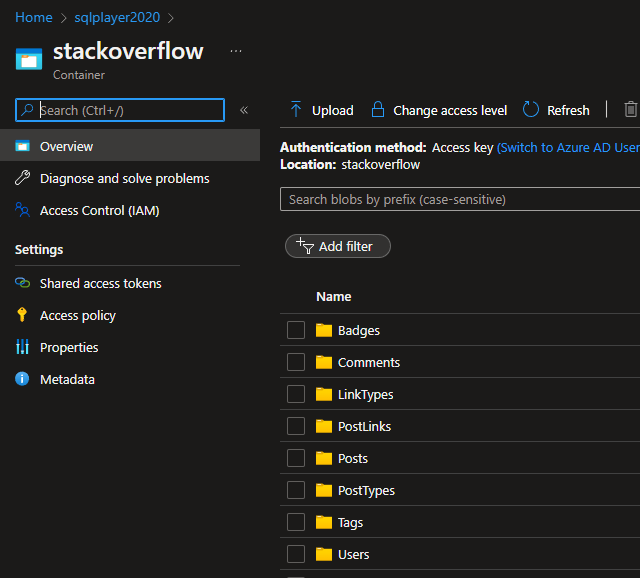
JobId
Unfortunately, right now, mounted storage is available only from one job, which is related to the notebook that runs mount function. That’s something which is totally different from Databricks and I don’t understand why it’s been implemented in this way. Hopefully it will be changed by Microsoft team soon.
As always – thanks for reading! I hope you found this post useful and it saved your time.
About author

You might also like

Synapse Analytics workspace – deployment challenges
Azure Synapse Analytics is not just “another service” in the Azure. It’s very comprehensive set of tools rather than one-goal-tool (like Azure Key Vault or even Storage Account). On the

{kind=link}
InvalidAbfsRestOperationException in Azure Synapse notebook
Problem The first issue that developers in my team noticed was when they tried to create database with Spark: Error message: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(meesage: Got exception: org.apache.hadoop.fs.azurebfs.contracts.exceptions.InvalidAbfsRestOperationException Status code: -1


2 Comments
Mounting Data Lake Storage from a Spark Pool – Curated SQL
July 19, 12:15[…] Kamil Nowinski runs into some trouble: […]
RK
August 07, 10:58Hi, I was trying to connection to blob storage gen2 via mountpoint, I was able to do this only if I am running from pipeline and if I run individually the code from synapse notebook cell, throwing authorization issue.could you please help on this.
User running having contributor role and the synapse workspace is having Azure blob contributor role already.