

Tokenization of database project in SSDT
SSDT project has something we call Variables. On the Internet (posts, forums) they also are known as placeholders or tokens, especially when talking in a deployment/CI/CD/DevOps context. Variables can be found for each SSDT database project: Right-click on the database project and choose “Properties”, afterward go to “SQLCMD Variables” section.
They are particularly useful when having more than one database project in a solution, but not only because the variables might be used in many variations and scenarios.
Predefined SQLCMD variables
For each project, we can use some variables already exists and hardcoded the project, which are:
- DefaultDataPath
- DefaultFilePrefix
- DatabaseName
- DefaultLogPath
Obviously, they can not be (re-)defined again on your list.
When might use variables?
There are a couple of specific cases when variables are particularly helpful, although, the list is not limited to these:
- (Other) Database References
- Linked Servers
- Login/users
- Variables for T-SQL code
- Define environment name/code
Database References
First of all, import all the databases you need to have into the solution. It’s obligatory to create a database reference when you have 3-part object references in T-SQL code. An imported code might look like this:
SELECT * FROM SecondDatabase.dbo.Customer
This is fine for SQL Server Engine, but it is not valid in SSDT project and as a result, you’ll get error or warning. What needs to be done then? You must add a database reference to [SecondDatabase] and replace ALL its occurrences in SSDT code using a newly created variable:
SELECT * FROM [$(SecondDatabase)].dbo.Customer
Once you create a new database reference – related variable will be created automatically for you.
Create new database reference (menu)
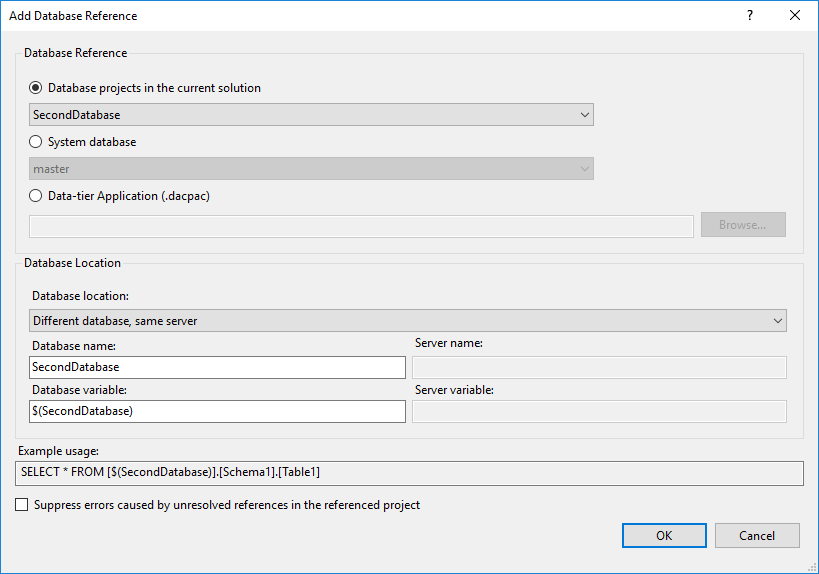
“Add Database Reference” (window)
In “Database Reference” you have 3 options to be chosen:
- Database projects in the current solution – this is the option we want to use referencing the SecondDatabase. In the list, you see all database project present in current solution, except the current database.
- System database – use this option when you must add a reference to [master] or [msdb]
- Data-tier Application (.dacpac) – this allows you to make a reference to a compiled version of a database project. Generally, I do not recommend using DACPAC files inside the solution, but sometimes it might be helpful in specific scenarios. This is another story for a separate blog post.
“Database location” determine where the referenced database is located in. We have 3 options over here:
- Same database – useful for specific cases, which we’ll be discussing in a future post.
- Different database, same server – the most-used option. Select it when a referenced database is located on the same server. That means we use 3-part object notation.
- Different database, different server – Choose that one when a referenced database is located on another server. In this case, you will use 4-part object notation, having 2 variables (server & database).
Choosing one of the above option – one or more fields below becomes available. For variable fields (Database variable, Server variable), by default, values are like $(database). I’d suggest to leave it like this unless you have a significant reason to change it. Notice, that for system databases – only “Database name” field is available. We do not use variables for them.
At the bottom of the window, we can see a usage example applying new variable(s).
When everything set up – click OK and new database reference will be created. You’ll see it on the list:
List of references databases
As I mentioned earlier here – the next step is to replace all occurrences with variables. This is the toughest one.
Also, be aware that although all variables would be replaced by their values which are exactly the same as they were – your code (Stored Procedures, Views, etc) change. It happens only for those references not being used brackets for server/database name.
-- Original code SELECT * FROM SecondDatabase.dbo.Customer; -- SSDT code with applied variable SELECT * FROM [$(SecondDatabase)].dbo.Customer; -- Code deployed from SSDT to physical database SELECT * FROM [SecondDatabase].dbo.Customer;
Don’t fool yourself – the whole process is not easy for bigger projects which contain many databases. The more databases and references you have – the more time you spend preparing all references to make the solution fully valid, i.e. without any errors and warnings.

Create DB reference
Every time when creating database reference – Visual Studio create one or two variables if it doesn’t exist in the project yet.
Create variable manually
The variables might be used in the various scenario, like:
- Define Environment Code (or name)
- Login and/or user
- Variables for T-SQL Variables (hard-coded values)
- Extra variables in order to control behavior in Pre/Post-deployment scripts
- Others…
From my experience and from your votes (I have asked for what reasons do you use SQLCMD Variables on Slack – #SSDT channel) results that the second most-used reason is holding an environment code in order to control the behavior of deployment in Pre/Post-deployment files.

Pool’s results: Which cases do you use SQLCMD Variables in your SSDT projects for?
This post is not aiming to describe in details all these scenarios, but let me show you one example. A good practice is to create user(s)/group in the database as they are on this level. Let’s do that using a variable.
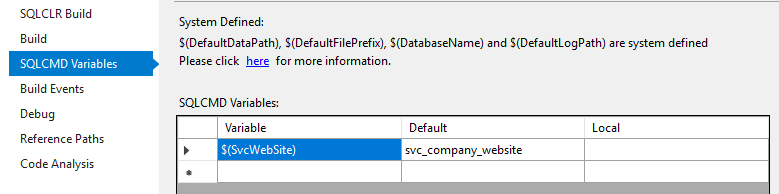
Firstly, add the variable in the database project with correspondent value:
$SvcWebSite = svc_company_website
Then, add the following rerunnable code to create user safety and grant appropriate permissions:
IF NOT EXISTS (SELECT 1 FROM sys.database_principals dp WHERE dp.name = '$(SvcWebSite)')
BEGIN
PRINT 'User [$(SvcWebSite)] created in [$(DatabaseName)] database.';
CREATE USER [$(SvcWebSite)] FROM LOGIN [$(SvcWebSite)];
END
EXEC sys.sp_addrolemember @rolename = 'db_datareader', @membername = [$(SvcWebSite)];
PRINT 'User [$(SvcWebSite)] was granted db_datareader role permissions in [$(DatabaseName)] database.';
GO
What is the advantage of that approach? Notice, that you can very easily change the value when deploying the database – having different users between environment (e.g. DEV, TEST, PreProd, PROD), for instance:
- DEV, TEST – svc_company_website_dev
- PrePROD, PROD – svc_company_website_prod
In a further post, I describe how to deploy the database directly (sic!) from Visual Studio and how to support it with publishing profiles.
Project file
So, adding references and variable we have made some changes to the project. As we all work with source control (I believe so!) it’s worth to know WHAT kind of changes should we expect.
The changes due to new database reference:
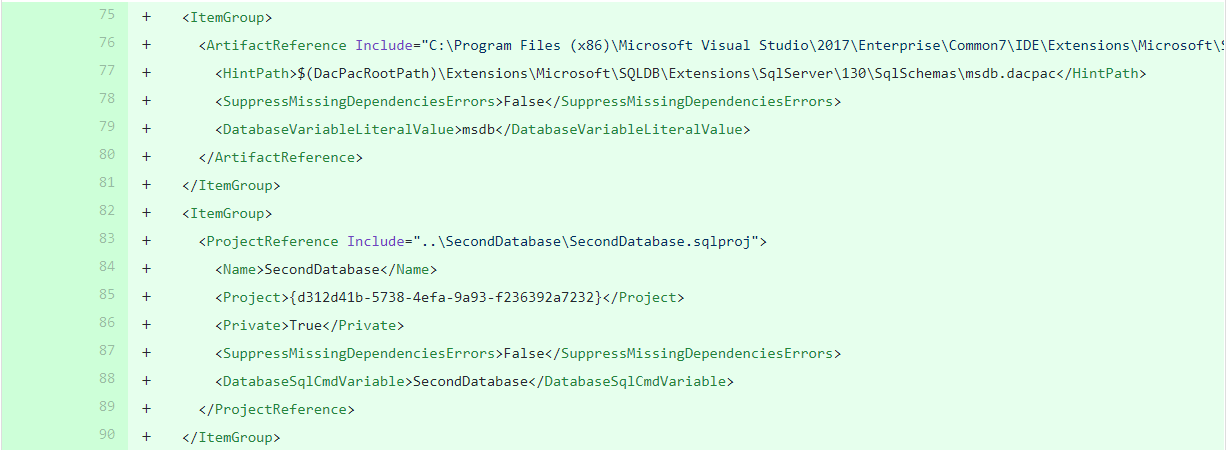
The changes due to new SQLCMD variable(s):
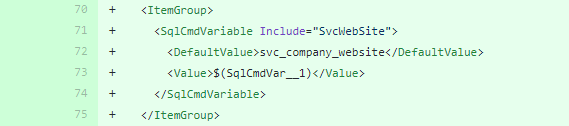
Ok, so we have got these variables/tokens in the code. How the hell will they be replaced in the physical database in a SQL server? That magic action happens during a deployment, hence keep reading.
The entire code of this post can be found in my Git repo: nowinskik/ssdt-demo
That’s it in this post. In the next post, I describe briefly how to deploy such a prepared database project to a physical target server.
Thanks for reading.
Updated @ 08/11/2019
This post is already part of the whole series about SSDT.
About author

You might also like

#TSQL2sDay – How SQLPackage.exe can spoil your deployment
Today, I’d like to describe briefly one thing with SQLPackage.exe. I know… It’s not precisely related to PowerShell (this week topic), but… you can use PowerShell to run it (and

Synapse Analytics workspace – deployment challenges
Azure Synapse Analytics is not just “another service” in the Azure. It’s very comprehensive set of tools rather than one-goal-tool (like Azure Key Vault or even Storage Account). On the

{kind=link}
ADF and passwords with Azure Key Vault & set up GIT
Have you worked with ADF yet? Did you configure the GIT code repository to automatically upload all changes to having your own isolated branch during development? If not yet, in


2 Comments
Ryan
September 01, 18:21Hi, what do you do if your database is sometimes on the same server and sometimes on a different server, depending on the deployment target? Particularly when using self-referencing server-name doesn’t work because it’s part of an alwayson availability replica?
Kamil Nowinski
September 04, 08:09Hi Ryan. Interesting problem, however, I do feel like I don’t have enough details. Firstly, I’m not sure why you want to deploy the same database onto a different server. If this is due to ‘AlwaysOn availability group’ scenario – you deploy only to primary replica and AO will do the rest. When connecting to the server you should always use the listener and the service forward the traffic to the right server (secondary replica if you specify Application Intent=ReadOnly, for example).
The other scenario you’re perhaps describing is when you’d like to connect from Stored Procedure Primary replica to the same (or another) database in the secondary replica. In that case, you may want to use Linked Server, however it must be very specific design and reason to do so in that way.