

Mapping Data Flow in Azure Data Factory (v2)
Introduction
Azure Data Factory is more of an orchestration tool than a data movement tool, yes. It’s like using SSIS, with control flows only. Once they add Mapping Data Flows to ADF(v2), you will be able to do native transformations as well, making it more like SSIS.
A couple of days ago (May 6th, 2019), Microsoft announced Azure Data Factory – Mapping Data Flow became to Public Preview. For many months I’ve had the pleasure of Private Preview access to test many scenarios, see how the product has evolved and how quickly review new features as they are added. I’m glad that I add my small contribution by raising some issues and helping to make it better. From today, you also have the chance to check how these functions work.
Mapping Data Flow
In the early Private Preview stage it was called Data Flow (without Mapping). However, if you know more tools and services from Microsoft’s stage – you knew that Power BI has had Data Flow too. And that was confusing because mainly they are a different set of features, except the fact both work on data.
At first, MDF (Mapping Data Flow) seems to be just another component on the pipeline map. However, if you look closely, you will notice that this component can do a lot more. A single MDF can contain a whole series of many transformations to finally obtain the desired data format, their granularity, quality and get rid of unwanted rows. If you know SSIS – it’s like Data Flow in SSIS (not exactly the same – I will come back to this topic later).
Mapping Data Flow must contain at least one source activity. The simplest version of it may be like this:

Just pull and push the data
But assuming you are copying data with like-for-like schema, it does not sound sensible because the same action can be made in ADF’s pipeline using “Copy Data” activity.
The situation will change very quickly when we add the desire to have an additional column. Standard “Copy Data” does not meet such a requirement. Mapping Data Flow comes with help where we can design a lot more complex data processing processes.
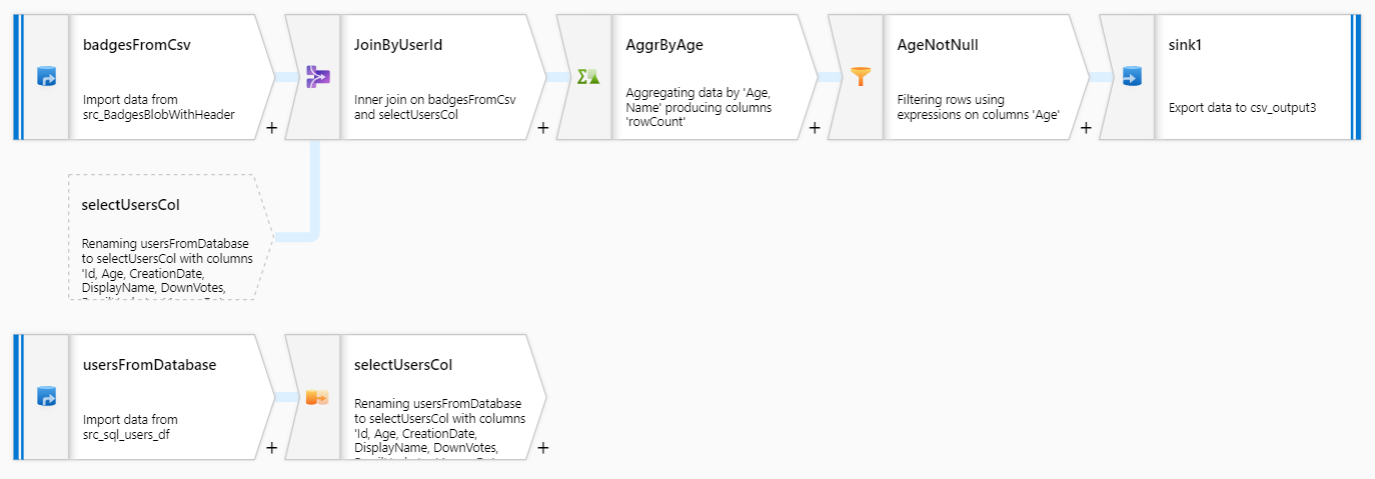
Several more components don’t make the Data Flow unreadable
Available activities
Let’s review what kind of options have been brought to the table.
At the moment you have the following operations (activities) available in Mapping Data Flow:
- Source
- New Branch
- Join
- Conditional Split
- Union
- Lookup
- Derived Column
- Surrogate Key
- Pivot
- Unpivot
- Window
- Exists
- Select
- Filter
- Sort
- Alter Row
- Sink
I’m sure that more activities appear in the future.
Now, having Mapping Data Flows you’re able to build Slowly Changing Dimension loading processes in ADF. If you want to see an example – create a pipeline from a template.

Azure Data Factory – Pipeline template gallery
Getting Started with ADF Mapping Data Flows
I’m not going to show you how to build the Mapping Data Flow step by step using a variety of activities. I will do a series of posts about selected activities of Mapping Data Flow to present them in full detail. In the meantime, the better way of introducing you to Mapping Data Flow would be video presentation I have given a few recent conferences. The last time I presented this topic was at the SQLBits conference in Manchester, UK.
Here you are – the entire video about Mapping Data Flow only:

Video: Mapping Data Flow – capabilities (SQLBits 2019 conference)
Is Data Factory SSIS in the cloud?
Generally yes, but… not thoroughly. There are a few aspects that need to be taken into account.
First of all – YES, because now we have capabilities to cover business logic with the data, such as data cleansing, transformation, aggregation, calculation. Therefore, you might perform all data preparation before pushing them to Azure SQL DW or ADLS (Azure Data Lake Storage).
And NO, because you can’t simply migrate your existing SSIS packages to Azure Data Factory. Although many similar operations exist, not everything is possible. For example, Event Handlers are not present as we know it from SSIS, as well as 3rd party components we could install in on-prem SQL Server Integration Services (SSIS).
| SSIS | ADF | |
|---|---|---|
| Feature | Control Flow | Pipeline |
| Feature | Data Flow | Mapping Data Flow |
| Connections | Connection Managers | Linked Services |
| 3rd party | Components | Templates |
If you are interested in taking a deeper look – check this page out where I compared SSIS components available in Data Flow to their equivalents in Mapping Data Flow.
Turning on Data Flow Debug mode
As you can see, there are many similarities between these tools. What’s happening behind the scenes is slightly different, though.
Azure Data Factory is metadata only. I mean, it doesn’t have its own engine. How does it go then?
When you run a pipeline which contains Mapping Data Flow component (activity) or run Debug mode in MDF – a Databricks cluster is spun up underneath for you. The entire Data Flow will be converted to Scala, compiled and built as JAR library and sent to the Spark Cluster.
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. The Databricks Runtime is built on top of Apache Spark and is natively built for the Azure cloud. Azure Databricks integrates deeply with Azure databases and stores: SQL Data Warehouse, Cosmos DB, Data Lake Store, and Blob Storage.
The key feature of Azure Databricks is its ability to blend and transform data at scale. That’s why Azure Data Factory and Databricks are ready to go with Big Data processes and plays a significant role in many modern Business Intelligence and Machine Learning solutions.
An Azure Databricks cluster utilised by ADF is fully managed by Microsoft and you have not got access to it.
Data exploration
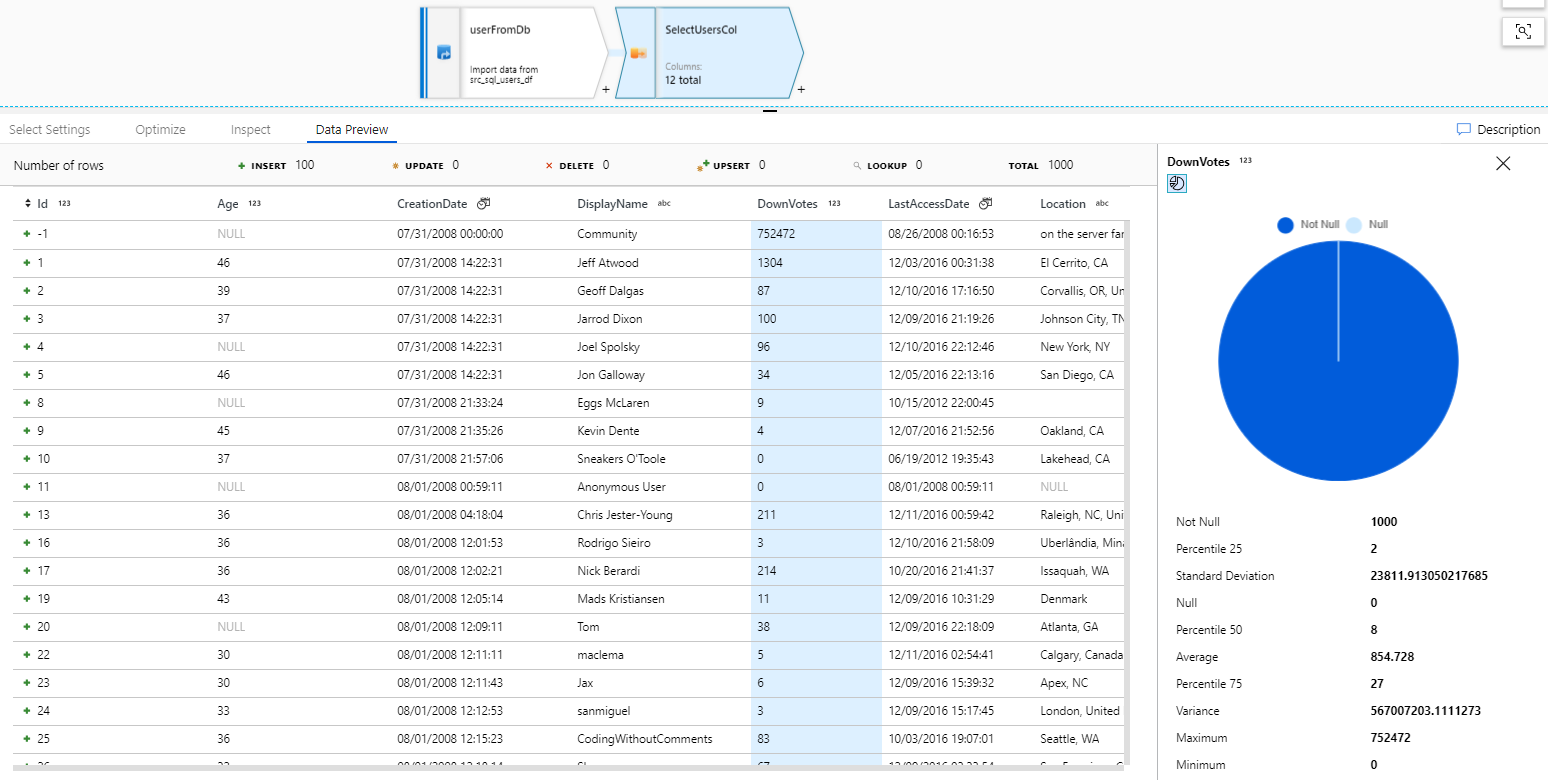
Data Preview panel in ADF Mapping Data Flow
One of the greater features in Mapping Data Flow is Data Flow Debug mode and capability called Data Preview. At each stage of the Mapping Data Flow (MDF) process, selecting any component – you can explore outgoing data in the bottom panel, which presents all columns, their data types, as well as basic statistics for the selected column.
That panel also shows you how many rows have been added, updated, deleted or upserted at this stage.
While selecting a column – on the right panel you’ll see statistics and metrics like values minimum, maximum, std deviation, percentiles (25, 50, 75), variance and average. Obviously, not all will be available for non-numeric data types.
Pretty cool, isn’t it?
Data Flow Execution Plan
Execution Plan shows you the whole road that data goes through from the source up to the sink (target) during an execution. Furthermore, the diagram is very readable and contains a lot of useful audit information about the executed flow. The general view presents all the sinks and transformations which took part in the Data Flow and information such as the number of processed rows, execution time per activity or whether a table has been cached by Spark or not.
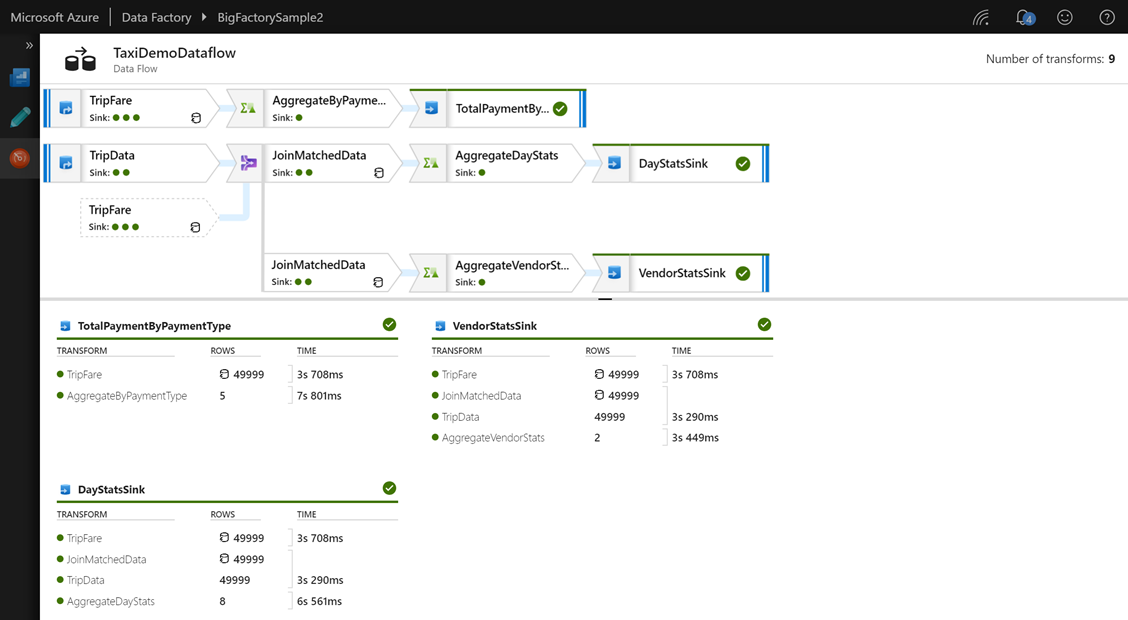
Mapping Data Flow – General View
When you click on a sink – you’ll see:
1) right-hand side panel – information about columns of that sink (target), stream information and partition chart.
2) bottom side panel – mapping for all sink’s columns and their origin (sources), including applied transformation methods.
Source & Target (sink)
Azure Data Factory is an orchestrator for data pipelines and supports many (90+) various connectors, including structured, semi or unstructured sources. As a mature tool, it supports multiple scenarios of working with files or database tables, either on source side or destination.
Multiple useful capabilities are supported for connectors, such as:
| Source transformation | Sink transformation |
|---|---|
|
|
Also, both, source and sink transformations support CSV/TSV and Parquet file format.
Alternative
As I mentioned above, Mapping Data Flow is converted to Scala to run it on Databricks. If you are more like a developer and love writing code – you can write the same process using all capabilities of Azure Databricks. Write down the code in Python, Scala, SQL, or even mixture of them all in one/multiple Databricks notebook(s), then execute them directly from Azure Data Factory leveraging Notebook activity.

Databricks Notebook Activities in ADF pipeline
It’s a very reasonable alternative in a case when you have more Python related skills in your team or do migrate existing Scala or Python solutions.
Have a look at this post which compares how to do the same things in Azure Databricks and with ADF Mapping Data Flow.
Conclusion
Azure Data Factory is one of the important components in every architecture diagram when building a modern data warehouse solution. Mapping Data flow has been a missing piece in the Azure Data Factory orchestration tool. Now, having that user-friendly UI which allows you to build end-to-end Big Data processes without the need to write code, means not only developers might use the service, but also teams of Business Analysts as well as Data Scientists.
It can successfully replace SSIS, especially in many greenfield projects.
About author

You might also like

Skirmishes with automated deployment of Azure Data Factory
When it comes to Azure Data Factory deployment, I always have a few words to say. You might be aware that there are two approaches in this terms. I was

Set up connection from Azure Data Factory to Databricks
Both, Azure Data Factory and Azure Databricks offer transformations at scale when it comes to ELT processing. On top of that, ADF allows you to orchestrate the whole solution in

){kind=link}
ADF – Continuous Integration & Deployment with Azure DevOps
Building CI/CD process for Azure Data Factory is not quite straightforward. Furthermore, there are a few different methods of doing that. Before we begin doing that, we must set up
Leave a Reply


13 Comments
Azure Data Factory Data Flow | James Serra's Blog
May 19, 05:17[…] Mapping Data Flow in Azure Data Factory (v2) […]
Ammy
August 23, 10:13Nice one. Cannot we take source from on premise ?
Kamil Nowinski
September 03, 22:08Thanks Ammy. No, not yet. SQL Server is not supported by ADF Mapping Data Flow as a source yet. To work around this issue you can use COPY activity before trigger data flow, which would prepare the data onto one of the supported sources:
– Azure Blob Storage
– Azure Data Lake Storage (Gen1 & Gen2)
– Azure SQL Data Warehouse
– Azure SQL Database
I’d recommend you leverage BLOB Storage as a staging.
Lakshman
September 16, 05:42Nice one. In my scenario Cosmos DB is my source and SQL Server is a destination. Is there any work around for this ?
I am not able to get proper Json formatted data even after copying to Blob storage as a staging. Data flow is not accepting Json formatted datasets as source. Any thoughts are appreciated.
Kamil Nowinski
September 20, 22:04Hello Lakshman. Yes, you can use Azure Cosmos DB (SQL API) as a source flattening output passing SQL query. Push the result to BLOB storage and then use it in Mapping Data Flow, if needed. This Gary Strange’s post also can help you in terms of flattening JSON files with ADF: https://medium.com/@gary.strange/flattening-json-in-azure-data-factory-2f2130794258
HTH
RC
September 18, 18:01Thanks this was really helpful, Our need is to load CosmosDB data incrementally to SQL server. Can this be achieved with out using blob storage?
Kamil Nowinski
October 16, 20:08Yes, you can. Now, pipelines offer much comprehensive mapping capabilities, so you can use them without blob storage and Mapping Data Flow in most cases.
Addend Analytics
December 09, 07:34This post was really helpful for my research as I was searching for an article related to the mapping Data Flow in Azure Data Factory. Thanks and keep sharing such informative articles.
Abhinav
January 22, 08:22Can I create a pipeline with data flow and data copy activity? I need to do merge copy from CSV files to blob and need data to be sorted on a single column.
Kamil Nowinski
October 16, 20:12Data copy activity is available in pipelines only. Do use it if you can. However, if your case requires transformations – you must leverage mapping data flow activity to satisfy your needs.
Aparna
June 10, 11:39Can we use sink for json files?
Kamil Nowinski
June 10, 12:04Yes, it seems to be possible. JSON type of DataSet is available for Sink in Mapping Data Flow.
Paweł
October 28, 14:09Would you consider to use MDF as replacement for TSQL stored procedures in [T]ransformation part in the Modern Data Warehouse?
Let’s say we have Data Lake Storage with raw data offloaded from onpremise and imagine we perform transformations with MDF on ADLS only. Later on we use copy activity/polybase to load data to databse.